
Pour que mes plugins de flux social soient performants, un des éléments essentiels à soigner est la formulation des requêtes sur la base de données. Pour mieux cerner cet enjeu, Freddy m’a conseillé de me baser sur un bouquin, très intéressant et très didactique, sur la question :
Bases de données – Concept, utilisation et développement (5e édition) Dunod, 2005. Hainaut, Jean-Luc. Paris: Dunod, 2005.
Cet article présente un schéma des tables que j’utilise dans mes plugins et décrit comment chaque requête est optimisée.
Schéma de la base de données
La première étape pour travailler est de réaliser un schéma clair des tables ciblées par les requêtes. Les deux tables en vert sont les deux tables créées par mon plugin de log et les autres tables sont les tables natives de Moodle.
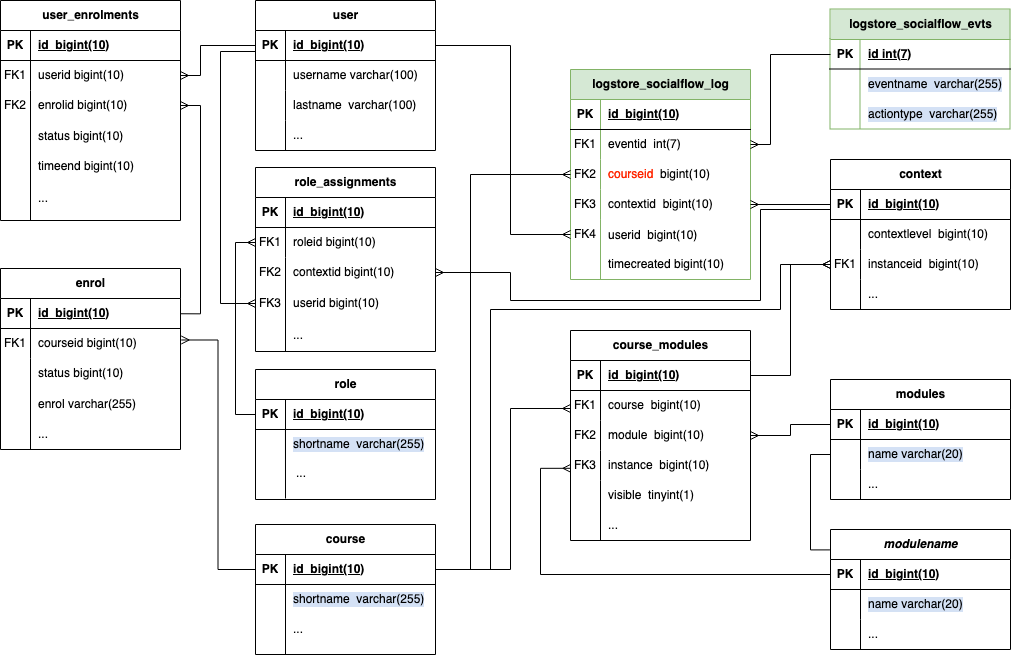
Les éléments surlignés en bleu sont les éléments dont j’ai besoin pour le flux social :
- à partir de la table role, je recherche le nombre d’étudiants inscrits au cours, en passant par les tables user_enrolments, enrol, role_assignments, context, course et user;
- dans la table course, je récupère le shortname du cours pour l’afficher dans mon tableau de flux social
- dans la table logstore_socialflow_evts, qui décrit les événements enregistrés, le champ eventname me permet de savoir à quel module cet action est liée et le champ actiontype décrit s’il s’agit d’une action de consultation ou de contribution;
- et le champ contextid de la table logstore_socialflow_log me permet de retrouver le module lié et d’accéder aux informations sur l’instance de ce module : le name et l’id permettrent d’afficher le titre de l’activité liée et le lien associé.
Requête de nettoyage de la table des logs
L’intérêt du flux social réside dans l’analyse des actions récentes des étudiants dans les cours. Pour que l’affichage des indicateurs reste performant, les données anciennes doivent être supprimées. Mais j’ai choisi de ne pas supprimer systématiquement les données anciennes de plus de 2 semaines, car il se peut qu’un étudiant ait réalisé une action il y a 3 semaines et que ses pairs se mobilisent seulement aujourd’hui pour la réaliser.
Donc l’idée est de supprimer les données sur les actions qui n’ont plus été réalisées par personne depuis 2 semaines.
Voici la formulation initiale de la requête :
SELECT id FROM {logstore_socialflow_log}
WHERE timecreated <= $loglifetime
AND contextid NOT IN (SELECT DISTINCT contextid FROM {logstore_socialflow_log} WHERE timecreated > $loglifetime)La requête est opérée sur une seule table. Elle peut sans doute être optimisée via un index sur le champ timecreated, et peut-être aussi sur le contextid, ou sur les deux.
Ensuite, je fais une suppression des lignes de la table associées à cette sélection par lot de 500, pour éviter une action de suppression massive qui planterait. Dans le plugin de learning analytics dont je m’inspire, il interrompt l’opération de suppression après un certain temps (300 secondes) et recommence. C’est une autre approche pour opérer la suppression par petites requêtes.
Requête pour extraire le nombre d’étudiants inscrits à un cours
Je choisis d’extraire les informations sur le nombre d’étudiants inscrits à chaque cours dans un tableau chargé préalablement, plutôt que de le recalculer pour chaque action. Parce qu’il y aura beaucoup d’actions liées au même cours et que cela ne sert à rien de refaire ce calcul.
La requête utilisée s’inspire d’une discussion sur Stackoverflow. Elle est complexe mais elle retourne le nombre d’utilisateurs inscrits dans le cours en prenant la précaution de vérifier que l’utilisateur n’est pas suspendu, que la méthode d’inscription liée n’est pas désactivée et que la durée de validité de l’inscription n’est pas dépassée …
SELECT COUNT(DISTINCT(u.id)) AS nbstu
FROM {user} u
INNER JOIN {user_enrolments} ue ON ue.userid = u.id
INNER JOIN {enrol} e ON e.id = ue.enrolid
INNER JOIN {role_assignments} ra ON ra.userid = u.id
INNER JOIN {context} ct ON ct.id = ra.contextid
AND ct.contextlevel = 50
INNER JOIN {course} c ON c.id = ct.instanceid
AND e.courseid = c.id
INNER JOIN {role} r ON r.id = ra.roleid
AND r.shortname = 'student'
WHERE e.status = 0 AND u.suspended = 0 AND u.deleted = 0 AND (ue.timeend = 0 OR ue.timeend > $now)
AND ue.status = 0 AND c.id = $courseid;
- $now est le timestamp actuel, calculé en PHP pour éviter les problèmes de désignation entre SQL et PosgreSQL.
- $courseid est l’id du cours pour lequel on calcule le nombre d’étudiants
Je n’ai rien trouvé de plus fiable dans l’API d’enrolment de Moodle.
J’ai ajouté les INNER aux jointures JOIN parce que cela permet de n’avoir que les lignes lorsque des valeurs correspondantes sont trouvées dans les deux tables. Cela me paraît plus sûr. Je me demande si ce ne serait pas plus efficace de mettre la contrainte sur le courseid au niveau de la jointure liée ?
Sur un Moodle tout nu, je ne vois pas d’index par défaut sur les tables, mais il me semble important de conseiller d’ajouter les index suivants pour le flux social:
- user : index individuels sur deleted et suspended ?
- user_enrolments : index conjoint sur userid et enrolid ? index individuel sur status et timeend ?
- role_assignments : index individuels sur userid, roleid et contextid ?
- context : index conjoint sur id et contextlevel ? index sur instanceid ?
- enrol : index sur courseid ? index sur status ?
Chez nous, je vois que Raoul en a ajouté sur notre Moodle de production :
- user : index notamment sur deleted (mais pas sur suspended)
- user_enrolments : index notamment sur le userid, enrolid, et je vois qu’il y a un index conjoint aussi userid/enrolid (pas d’index sur timeend et status car sans doute moins souvent utilisés dans les requêtes)
- role_assignment : index notamment sur le userid, le contextid et le roleid, et un index conjoint sur roleid/contextid et un index conjoint sur userid/contextid/roleid
- context : index notamment sur le contextlevel et instance id
- enrol : index notamment sur le courseid et roleid (mais pas sur le status, sans doute utilisé plus rarement)
Je ne vois pas de raison de commencer par les jointures dans la table role_assignements plutôt que de passer par les jointures sur la table user_enrolments. En théorie, un utilisateur peut avoir plusieurs rôles dans un cours lié à une même inscription, donc cela me semble plus performant comme cela. Mais un étudiant n’aura pas plusieurs rôles dans un cours …
Pour tester, j’ai exécuté la requête sur un cours de notre Moodle de production sur un cours à plus de 250 étudiants, la requête prend 119 msec. Ca veut dire que si j’exécute cette requête une dizaine de fois, cela prendra de l’ordre d’une seconde rien que pour avoir le nombre d’étudiants dans chaque cours …
Requête principale pour afficher la liste d’informations du flux social
La requête pour le flux social consiste à extraire les lignes de la table de log lié aux bons cours et à la période pertinente, et à les afficher de manière aggrégée.
Si l’étudiant souhaite afficher le flux social pour les cours qui ont les id 7,6,4,2,3, qui ont respectivement 24,20,12,19,14 étudiants et qu’il choisit d’afficher 10 éléments dans le bloc, la requête est la suivante :
SELECT log.contextid,log.eventid,log.courseid, evts.actiontype,
CASE
WHEN log.courseid =7 THEN COUNT(DISTINCT log.userid)/24 WHEN log.courseid =6 THEN COUNT(DISTINCT log.userid)/20 WHEN log.courseid =4 THEN COUNT(DISTINCT log.userid)/12 WHEN log.courseid =2 THEN COUNT(DISTINCT log.userid)/19 WHEN log.courseid =3 THEN COUNT(DISTINCT log.userid)/14 END AS freq
FROM {logstore_socialflow_log} log
INNER JOIN {logstore_socialflow_evts} evts ON (log.eventid=evts.id)
WHERE log.courseid IN (7,6,4,2,3) AND log.timecreated > 1712149184 GROUP BY log.contextid, log.eventid, log.courseid ORDER BY freq DESC LIMIT 10; De manière générique, la requête avec les fonctions PHP sur les id de cours est la suivante :
$sql = "SELECT log.contextid,log.eventid,,log.courseid evts.actiontype, ";
$sql.="CASE ";
foreach ($currentcourses as $id) {
$nbstu=$coursenbstu[$id];
$sql.= "WHEN log.courseid =".$id." THEN COUNT(DISTINCT log.userid)/".$nbstu." ";
}
$sql.=" END AS freq ";
$sql.="FROM {logstore_socialflow_log} log INNER JOIN {logstore_socialflow_evts} evts ON (log.eventid=evts.id)
WHERE log.courseid IN ($currentcoursesstring) AND log.timecreated > $loglifetime $clausetype
GROUP BY log.contextid, log.eventid, log.courseid
ORDER BY freq DESC LIMIT ".$currentitemnum.";";- le tableau $currentcourses contient la liste des cours sélectionnés par l’utilisateur
- le tableau $coursenbstu est un tableau associatif qui permet d’obtenir le nombre d’étudiants sur base de l’id du cours
- $currentcoursesstring contient la liste des id de cours sélectionnés par l’utilisateur concaténés dans une chaîne de caractère avec la virgule comme séparateur
- $clausetype contient une chaine lié à la restriction sur le type d’actions ciblée, s’il n’y a que les actions de contribution à afficher, elle vaut « AND evts.actiontype=’contrib’ »
- $currentitemnum est le nombre d’items à afficher choisi par l’utilisateur
Dans cette requête, les points d’attention sont les suivants :
- l’index sur le courseid est sans doute un excellent moyen d’accélérer toutes les requêtes quand on a beaucoup de cours
- un index sur le userid pourrait accéler le COUNT sur cette colonne
- un index sur le timecreated qui est un champ croissant dans la table devrait aussi améliorer la situation, a moins que l’idéal ne soit un index conjoint sur courseid et timecreated ? Toutes les valeurs de timecreated sont différentes, dont ça risque d’être lourd un index conjoint de ce type …
- peut-être aussi évaluer l’intérêt d’un index sur les clauses group by ?
– si je prends les 3 y aura autant de lignes que d’actions réalisées sur un élement dans un cours, sans doute pertinent s’il ya beaucoup d’étudiants dans les cours, mais je doute de l’intérêt général
– sur la ou les clauses les plus contraignantes du group by ? peut-être l’eventid ? ça permettrait de diviser par 30 le nombre des lignes, si les actions étaient réparties de manière équitables, mais les actions ne sont pas réparties de manière équitable donc l’efficacité sera variable
– sur le courseid et le eventid ? ça fait de très petits cluster des actions d’un type dans un cours, sans doute pas très efficace, dépend aussi du nombre d’étudiants dans le cours
Sur base du contextid, dans une requête secondaire, je repêcherai les informations sur l’activité ciblée par l’action. Cela me semble plus simple de procéder de cette manière puisque le bloc de flux social n’affiche que les premiers éléments de la liste. Si je composais un rapport plus détaillé, ce choix pourrait être rediscutée.
Il faudra trouver un moyer de tester cette requête sur des données réelles.
Requêtes secondaires pour afficher les informations liées à un événement du flux social
Pour obtenir les informations détaillées sur une activité ou ressource liée à un contextid, je dois procéder en 2 temps parce que la première étape est de savoir de quel type d’activite il s’agit pour savoir dans quelle table chercher.
La requête pour aller du contextid au modulename et à l’id d’instance :
SELECT cm.instance, m.name
INNER JOIN {context} c ON id=$contextid
INNER JOIN {course_modules} cm ON cm.id=c.instanceid
INNER JOIN {modules} m ON m.id=cm.module
WHERE cm.visible=1La requête pour aller jusqu’au titre et à l’id de l’activité (permet aussi de générer le lien direct vers la ressource ou activité) :
SELECT name FROM $modulename WHERE id=$instanceDans la mesure où ces requêtes reposent sur des sélections sur base de clés primaires dans les tables, il n’y a pas de besoin d’optimisation particulière de ces requêtes.
Mais j’ai un problème : si une des activités est cachée, ma liste n’affichera que 9 éléments. Je dois réussir à récupérer tout en une seule requête …
Requête SIMPLIFIEE pour obtenir les informations pour le flux social
Pour garder les 10 premiers événements liés à des activités visible, la requête pour les mêmes données que dans l’exemple ci-dessus devient :
SELECT log.contextid, log.eventid, log.courseid, evts.actiontype, c.instanceid, cm.instance, m.name,
CASE
WHEN log.courseid =7 THEN COUNT(DISTINCT log.userid)/24 WHEN log.courseid =6 THEN COUNT(DISTINCT log.userid)/20 WHEN log.courseid =4 THEN COUNT(DISTINCT log.userid)/12 WHEN log.courseid =2 THEN COUNT(DISTINCT log.userid)/19 WHEN log.courseid =3 THEN COUNT(DISTINCT log.userid)/14 END AS freq
FROM {logstore_socialflow_log} log
INNER JOIN {logstore_socialflow_evts} evts ON (log.eventid=evts.id)
INNER JOIN {context} c ON (log.contextid=c.id)
INNER JOIN {course_modules} cm ON (c.instanceid=cm.id) INNER JOIN {modules} m ON (cm.module=m.id)
WHERE log.courseid IN (7,6,4,2,3) AND log.timecreated > 1712161036 AND cm.visible=1 GROUP BY log.contextid, log.eventid, log.courseid
ORDER BY freq DESC LIMIT 10; Et écrit de manière générique …
$sql = "SELECT log.contextid, log.eventid, log.courseid, evts.actiontype, c.instanceid, cm.instance, m.name, ";
$sql.="CASE ";
foreach ($currentcourses as $id) {
$nbstu=$coursenbstu[$id];
$sql.= "WHEN log.courseid =".$id."
THEN COUNT(DISTINCT log.userid)/".$nbstu." ";
}
$sql.="END AS freq ";
$sql.="FROM {logstore_socialflow_log} log
INNER JOIN {logstore_socialflow_evts} evts ON (log.eventid=evts.id)
INNER JOIN {context} c ON (log.contextid=c.id)
INNER JOIN {course_modules} cm ON (c.instanceid=cm.id)
INNER JOIN {modules} m ON (cm.module=m.id)
WHERE log.courseid IN ($currentcoursesstring) AND log.timecreated > $loglifetime AND cm.visible=1 $clausetype
GROUP BY log.contextid, log.eventid, log.courseid
ORDER BY freq DESC LIMIT ".$currentitemnum.";";Cette requête ne me semblent pas nécessiter plus de préoccupation que la première version puisque les jointures ajoutées concernent des tables externes et elles sont liées à des clés primaires de ces tables.
Les points d’attention pour la table des logs restent les suivants :
- l’index sur le courseid est sans doute un excellent moyen d’accélérer toutes les requêtes quand on a beaucoup de cours
- un index sur le contextid est aussi intéressant à prévoir
- un index sur le userid pourrait accéler le COUNT sur cette colonne
- un index sur le timecreated qui est un champ croissant dans la table devrait aussi améliorer la situation, a moins que l’idéal ne soit un index conjoint sur courseid et timecreated ? Toutes les valeurs de timecreated sont différentes, dont ça risque d’être lourd un index conjoint de ce type …
- peut-être aussi évaluer l’intérêt d’un index sur les clauses group by ?
– si je prends les 3, il y aura autant de lignes que d’actions réalisées sur un élement dans un cours, sans doute pertinent s’il y a beaucoup d’étudiants dans les cours, mais je doute de l’intérêt général
– sur la ou les clauses les plus contraignantes du group by ? peut-être l’eventid ? ça permettrait de diviser par 30 le nombre des lignes, si les actions étaient réparties de manière équitables, mais les actions ne sont pas réparties de manière équitable donc l’efficacité sera variable
– sur le courseid et le eventid ? ça fait de très petits cluster des actions d’un type dans un cours, sans doute pas très efficace, dépend aussi du nombre d’étudiants dans le cours
La requête pour aller jusqu’au titre et à l’id de l’activité (permet aussi de générer le lien direct vers la ressource ou activité) :
SELECT name FROM $modulename WHERE id=$instanceDans la mesure où cette requête reposent sur des sélections sur base de clés primaires dans les tables, il n’y a pas de besoin d’optimisation particulière de cette requête.
Requête pour déterminer si un étudiant a réalisé ou pas une actioN
La dernière requête est celle qui permet de déterminer si l’utilisateur actuel a fait ou pas un action du flux social.
SELECT COUNT(id) AS nbdone
FROM {logstore_socialflow_log}
WHERE courseid=$courseid
AND contextid=$contextid
AND eventid=$eventid
AND userid=$cuserid- Dans cette requête, le fait d’avoir un index sur courseid devrait déjà améliorer fortement sa performance et un index sur le userid est sans doute aussi pertinent pour cette requête.
- Je ne sais pas si ajouter un index sur un autre élément ou sur un index conjoint pourrait aider, mais je pourrais l’objectiver lors de mes tests. Mais une fois encore, cela va dépendre des données:
beaucoup ou peu de cours ? 7000 chez nous
avec beaucoup ou peu d’étudiants ? 100 en moyenne chez nous
avec beaucoup ou peu d’actions ? plutôt beaucoup et pas réparties de manière équitable puisque les différents types d’activités Moodle ne sont pas utilisées de manière équitable
L’index conjoint courseid/userid veut sans doute la peine d’être tenté. Ca fera autant de ligne que d’inscription, ce qui est encore raisonnable.
Vérifier l’optimisation des index sur la table des logs
Pour vérifier l’optimisation des index sur la table des logs, je vois 3 approches qui peuvent toutes les 3 être menées :
- discuter de cet article avec Raoul et voir comment analyser l’intérêt des index sur une base de données à chaud
- faire une copie de la table des log standards de Moodle dans une base de données séparée, adapter le script d’import du plugin de log de learning analytics et tester les requêtes en direct sur la table
Après discussion avec Raoul, je découvre la commande SQL EXPLAIN ANALYZE (VERBOSE) qui décrit le temps d’exécution de chaque partie d’une requête SQL. L’idéal est d’utiliser cette commande pour voir quelle partie d’une requête est la plus coûteuse et tenter une reformulation. Il faut à tout prix éviter qu’une reqête génère un scan complet d’une table.
Points de discussion intéressants :
- l’ordre des requêtes AND n’a pas d’importance, mais bien celui des OR;
- les éléments ORDER BY et LIMIT ne justifient pas l’ajout d’index;
- les éléments GROUP BY justifient souvent l’ajout d’index;
- pour la dernière requête, l’ajout d’un index sur les 4 colonnes du WHERE rendrait la requête instantannée et il ne faut pas hésiter à l’envisager;
- s’il est pertinent d’ajouter des index sur d’autres tables que celles du plugin, le plugin d’installe peut sans doute le faire
S’il était impossible de rendre les requêtes actuelles performantes, il faudrait revoir la structure de mes données. Une piste qui pourrait être envisagée pourrait être de
- créer une table avec les id de cours et le nombre de participanst actifs, mise à jour chaque nuit via une tâche cron, pour éviter de recalculer ce nombre à chaque fois qu’un utilisateur charge le bloc de flux social
- construire une table de log aggrégée, comme dans le plugin Learning Analytics, avec juste le nombre d’occurences d’un event
- stocker les informations sur les actions utilisateur dans une autre table
Avec une telle structure, les requêtes devraient être à coup sûr performantes.
Raoul va me donner accès à une copie de la BDD de production pour que je teste mes requêtes. Je dois intégrer le script d’import des données depuis la table des log standard et je pourrai tester cela.
Temps de travail sur cet article : 2 jour