
Si la nouvelle structure permet de rendre l’affichage du flux social performant, il faut à présent se préoccuper de l’optimisation des requêtes d’écriture …
La structure ci-dessous est le résultat des tests de cet article :
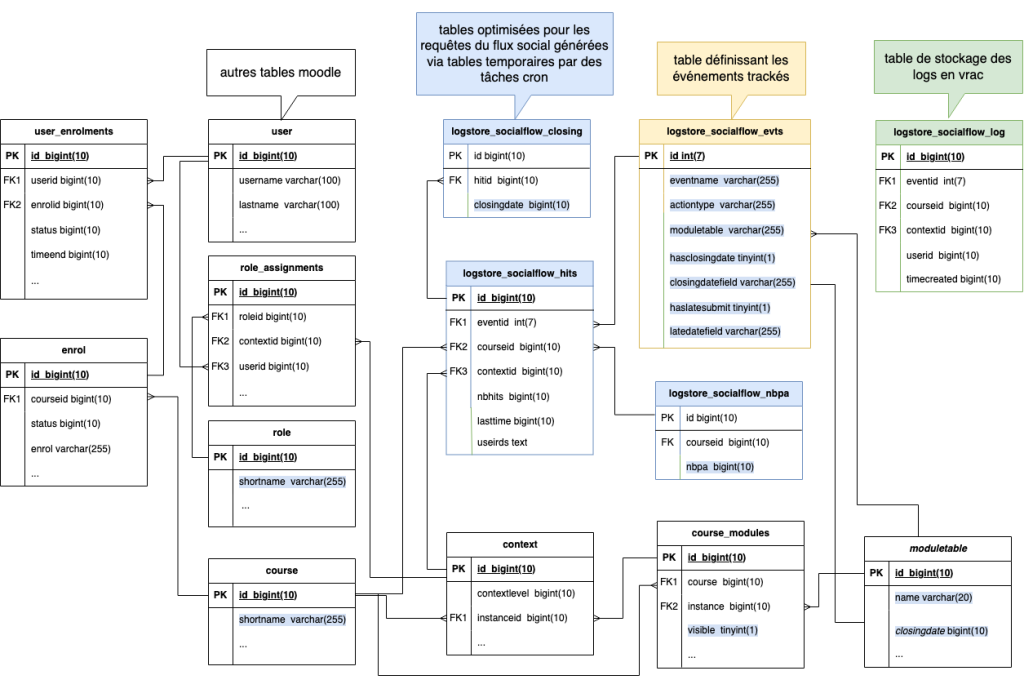
Requêtes d’écriture dans les tables de logs
Dans le fichier store.php, je dois utiliser la fonction générique insert_record pour insérer un enregistrement dans la base de donnée.
En PosgreSQL, cela revient à faire un requête de cette forme :
INSERT INTO mdl_logstore_socialflow_log (eventid, courseid, contextid, userid, timecreated) VALUES (11, 2222, 579245 ,77649, 1712926004);Temps d’exécution : 100ms
A présent, chaque action de log donne lieu à plusieurs tests et actions d’écriture.
Tester s’il y a déjà une ligne associée à la paire (eventid, contextid) dans la table de log :
- si non, l’ajouter et ajouter la ligne équivalente dans les logs utilisateur
- si oui, tester s’il y a déjà une ligne liée à ce userid dans la table des logs utlisateur
- si non, faire un update de la ligne dans la table des logs pour ajouter 1 aux hits et ajouter une ligne dans la table des logs utilisateurs
- si oui, mettre a jour le lasttime de lal igne associée dans la table de log utilisateur
La première requête consiste à tester si une ligne existe déjà pour la paire (eventid,contextid) :
SELECT * FROM mdl_logstore_socialflow_hits_log WHERE courseid=11 AND eventid=11 AND contextid=579245Temps d’exécution : 500 ms et avec un index sur les 2 colonnes (contextid order décroissant, puis eventid), ça ne change rien … Quoi que je fasse sur les index, ça ne change rien … Vaut-il mieux passer par une table temporaire pour calculer les hits ? J’arrête là et je teste au point suivant …
APPROCHE ALTERNATIVE : Recalculer toute lA table de hits
SELECT log.contextid,log.eventid,log.courseid,COUNT(DISTINCT log.userid) AS hits
FROM mdl_logstore_socialflow_log log
WHERE log.timecreated > 1712149184 GROUP BY log.contextid, log.eventid, log.courseid;Ca prend 8 secondes ! Ce sera beaucoup plus rapide que d’essayer de mettre à jour les données ligne par ligne à chaque action utilisateur. Voir si les index peuvent aider ? Il y a déjà les index qu’il faut pour le flux social.
J’y intègre le latstime et la liste des ids des users associés. Ca m’évite d’avoir à construire une nouvelle table pour avoir la liste des utilisateurs qui ont fait une action. Comme Moodle doit fonctionner avec n’importe quel SGBD et comme je ne dois pas faire de recherche sur le champ qui agglomère les id utilisateurs, je fais un champ TEXT pour agglomérer les données (JSON aurait sans doute été mieux mais seulement supporté par MySQL et PosgreSQL). (Merci chatGPT pour les conseils sur ce point !)
SELECT log.contextid,log.eventid,log.courseid, COUNT(DISTINCT log.userid) AS hits, MAX(log.timecreated) AS lasttime, STRING_AGG(userid::TEXT, ',' ORDER BY userid) AS userids
FROM mdl_logstore_socialflow_log log
WHERE log.timecreated > 1712149184 GROUP BY log.contextid, log.eventid, log.courseid;Temps d’exécution : 39 secondes !
Mais avec la table des participants du cours, j’ai toutes les infos qu’il me faut pour afficher le flux social.
Il faut que je configure 2 tâches cron avec des délais d’exécution différents :
- une tâche qui calcule le nombre de participants dans le cours toutes les nuits ou 2 fois par jour
- une tâche qui recalcule les données de la table des hits configurée par défaut pour tourner toutes les heures par exemple
Pour récupérer les données en PHP :
$userids = unserialize($row['userids']);Pour vérifier si un étudiant a réalisé l’action :
$userid_to_check = 77456;
if (in_array($user_id_to_check, $userids)) ...Les conseils de ChatGPT pour gérer les erreurs …
Bonnes Pratiques
- Validation des Données :
Assurez-vous que les données à sérialiser sont bien formatées et valides.
if (is_array($user_ids)) {
$serialized_user_ids = serialize($user_ids);
} else {
throw new Exception('Invalid data format for user_ids');
} 2. Gestion des Erreurs :
Gérez les exceptions et les erreurs lors des opérations de sérialisation et de base de données.
try {
$user_ids = serialize([1, 2, 3]);
$query = "INSERT INTO mdl_plugin_hits (action, action_date, user_ids) VALUES ('login', '2024-05-31', :user_ids)";
$stmt = $pdo->prepare($query);
$stmt->execute([':user_ids' => $user_ids]);
} catch (Exception $e) {
echo "Erreur : " . $e->getMessage();
} 3. Sécurité :
Faites attention aux données désérialisées, car des données malveillantes pourraient causer des problèmes de sécurité.
$serialized_data = $row['user_ids'];
if (@unserialize($serialized_data) === false) {
throw new Exception('Failed to unserialize data');
} else {
$user_ids = unserialize($serialized_data);
}
Analyse de LA REQUETE QUI PERMETTRAIT DE COMPOSER la table pour les logs utilisateurs
Et si j’essayais quand même de créer la table de log utilisateur, ça coûterait compien ?
SELECT h.id, l.userid
FROM mdl_logstore_socialflow_log l
JOIN mdl_logstore_socialflow_hits_log h ON l.contextid=h.contextid AND l.eventid=h.eventid AND l.courseid=h.courseidTemps d’exécution : 16 minutes
C’est une jointure entre un table de 2 millions de lignes et une table de 150000 lignes, c’est impossible. Et plus il y aura de données plus cette requête sera non performante. Je reste sur l’idée d’une table de hits avec le liste des userids agglomérés dans un champ.
Gestion de la closingdate
Pour gérer efficacement les closingdate, il faut éviter d’envisager de les gérer à l’écriture mais penser à une solution pour les générer via requête SQL. Le problème c’est que les jointures ne sont pas évidentes puisque les closingdates ne sont pas toujours encodées via le même champ.
Mais il serait possible d’écrire une requête qui extrait la liste des champ qui peuvent détenir les closingdates (il y en a 2 pour nos events) et sur base du résultat, écrire autant de requêtes que d’event avec closingdate qui extraient les infos sur les closing dates.
SELECT id, eventname,moduletable,closingdatefield FROM mdl_logstore_socialflow_evts WHERE hasclosingdate>0Temps d’exécution : 50ms
L’idée serait alors de mettre les infos sur les closingdates dans une table temporaire séparée, alimentée via plusieurs requêtes, une pour chaque ligne avec $eventid, $moduletable, $closingdatefield:
SELECT DISTINCT(h.id), mt.$closingdatefield
FROM mdl_logstore_socialflow_hits h
INNER JOIN
mdl_logstore_socialflow_evts evts ON h.eventid = $eventid
INNER JOIN
mdl_context c ON h.contextid = c.id
INNER JOIN
mdl_course_modules cm ON c.instanceid = cm.id
INNER JOIN
$moduletable mt ON cm.instance=id.mt
WHERE
(mt.$closingdatefield NOT NULL) AND (mt.$closingdatefield > 0)Selon le module, quand il n’y a pas de closingdate, la valeur par défaut est soit null, soit 0. La double condition permet de faire face à toutes les situations et pour tous les SGBD supportés par Moodle.
Pour le devoir, cela donne ceci :
SELECT DISTINCT(h.id), mt.cutoffdate
FROM mdl_logstore_socialflow_hits_log h
INNER JOIN
mdl_logstore_socialflow_evts evts ON h.eventid = 2
INNER JOIN
mdl_context c ON h.contextid = c.id
INNER JOIN
mdl_course_modules cm ON c.instanceid = cm.id
INNER JOIN
mdl_assign mt ON cm.instance=mt.id
WHERE
(mt.cutoffdate IS NOT NULL) AND (mt.cutoffdate > 0)Temps d’exécution : 85 ms !
Pour le quiz :
SELECT DISTINCT(h.id), mt.timeclose
FROM mdl_logstore_socialflow_hits_log h
INNER JOIN
mdl_logstore_socialflow_evts evts ON h.eventid = 28
INNER JOIN
mdl_context c ON h.contextid = c.id
INNER JOIN
mdl_course_modules cm ON c.instanceid = cm.id
INNER JOIN
mdl_quiz mt ON cm.instance=mt.id
WHERE
(mt.timeclose IS NOT NULL) AND (mt.timeclose > 0)Temps d’exécution : 100 ms
Il devrait y avoir une dizaine de requêtes de ce genre, donc en 1 seconde, je devrais pouvoir avoir les infos dur les closing dates !
Et ce n’est pas méga important de mettre ces infos à jour tout le temps.
Remarque sur l’écriture des requêtes dans Moodle
Je note déjà que pour écrire des requêtes génériques dans Moodle, je vais devoir utiliser la database api :
https://moodledev.io/docs/4.4/apis/core/dml
Et il y a bien une commande rename_table dans cette liste de commandes.
Ce sera pratique pour la mise à jour des tables temporaires.
Temps de travail sur cet article : 1/2 jour