Don’t use ping for accurate delay measurements
The ping software was designed decades ago to verify the reachability of a given IPv4 address. For this, it relies on ICMP that runs on top of IPv4. A host that receives an ICMP echo request message is supposed to reply immediately by sending an ICMP echo reply message. This confirms the reachability of the remote host. By measuring the delay between the transmission of the echo request message and the reception of the echo reply message, it is possible to infer the round-trip-time between the two hosts. Since the round-trip-time is important for the performance of many Internet protocols, this is an important metric which is reported by ping. Some variants of ping also report the minimum and maximum delays after measuring a number of round-trip-times. A typical example is shown below
ping www.psg.com
PING psg.com (147.28.0.62): 56 data bytes
64 bytes from 147.28.0.62: icmp_seq=0 ttl=48 time=148.715 ms
64 bytes from 147.28.0.62: icmp_seq=1 ttl=48 time=163.814 ms
64 bytes from 147.28.0.62: icmp_seq=2 ttl=48 time=148.780 ms
64 bytes from 147.28.0.62: icmp_seq=3 ttl=48 time=153.456 ms
64 bytes from 147.28.0.62: icmp_seq=4 ttl=48 time=148.935 ms
64 bytes from 147.28.0.62: icmp_seq=5 ttl=48 time=153.647 ms
64 bytes from 147.28.0.62: icmp_seq=6 ttl=48 time=148.682 ms
64 bytes from 147.28.0.62: icmp_seq=7 ttl=48 time=163.926 ms
64 bytes from 147.28.0.62: icmp_seq=8 ttl=48 time=148.669 ms
64 bytes from 147.28.0.62: icmp_seq=9 ttl=48 time=153.352 ms
64 bytes from 147.28.0.62: icmp_seq=10 ttl=48 time=163.688 ms
64 bytes from 147.28.0.62: icmp_seq=11 ttl=48 time=148.729 ms
64 bytes from 147.28.0.62: icmp_seq=12 ttl=48 time=163.691 ms
64 bytes from 147.28.0.62: icmp_seq=13 ttl=48 time=148.536 ms
^C
--- psg.com ping statistics ---
14 packets transmitted, 14 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 148.536/154.044/163.926/6.429 ms
In Computer Networking, Principles, Protocols and Practice, the following figure was used to illustrate the variation of the round-trip-time. This measurement was taken more than ten years ago between a host connected to a CATV modem in Charleroi and a server at the University of Namur. The main reason for the delay variations were the utilisation of the low speed link that we used at that time.
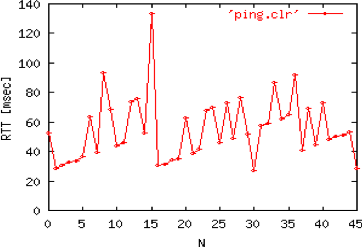
Evolution of the round-trip-time between two hosts
In a recent presentation at RIPE66, Randy Bush and several of his colleagues revealed some unexpected measurements collected by using ping. For these measurements, they used two unloaded servers and sent pings through mainly backbone networks. The figure below shows the CDF of the measured delays. The staircase curves were the first curves that they obtained. These delays look strange and several plateaux appear but it is not easy to find a clear explanation immediately.
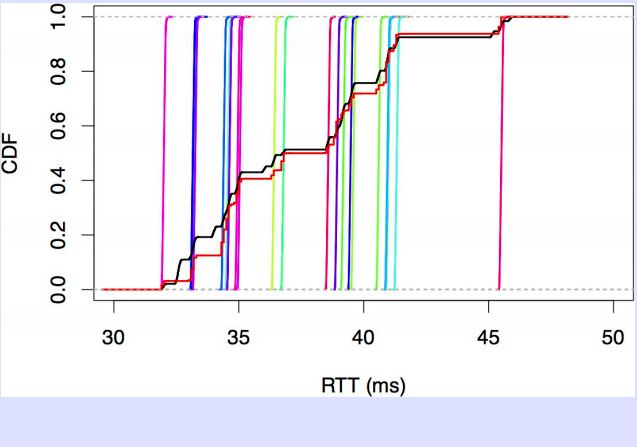
They studied these delays in more details and tried to understand the reason for the huge delay variations that they observed. To understand the source of the delay variations, it is useful to look back at the format of an ICMP message encapsulated inside an IPv4 packet.

The important part in this header is the first 32 bits word of the ICMPv4 header. For TCP and UDP, this word contains the source and destination ports of the transport flow. Many routers that support Equal Cost Multipath will compute a hash function over the source and destination IP addresses and ports for packets carrying TCP/UDP segments. However, how should such a load balancing router handle ICMP messages or other types of protocols that run directly on top of IPv4. A first option would be to always send ICMP messages over the same path, i.e. disable load balancing for ICMP messages. This is probably not a good idea from an operational viewpoint since this would imply that ICMP messages, that are often used for debugging, would not necessarily follow the same paths as regular packets. A better option would be to only use the source and destination IP addresses when load balancing ICMP messages. However, this requires the router to detect distinguish between UDP/TCP and other types of flows and react in function of the Protocol field of the IP header. This likely increases the cost of implementing load-balancing in hardware. The measurements presented above are probably, at least partially, caused by load-balancing routers that use the first 32 bits word of the IP payload to make their load balancing decision, without verifying the Protocol field in the IP header. The vertical bars shown in the figure above correspond to a modified ping that always send ICMP messages that start with the same first 32 bits word. However, this does not completely explain why there is a delay difference of more than 15 milliseconds on the equal cost paths between two servers. Something else might be happening in this network.
Additional details are discussed in On the suitability of ping to measure latency by Cristel Pelsser, Luca Cittadini, Stefano Vissicchio and Randy Bush. See https://ripe66.ripe.net/archives/video/12/ for the recorded video.
Disruption free reconfiguration for link-state routing protocols implementable on real routers
Link state routing protocols like OSPF and IS-IS flood information about the network topology to all routers. When a link needs to be shutdown or its weight changes, a new link state packet is flooded again. Each router processes the received link state packet and updates its forwarding table. Updating the forwarding table of all routers inside a large network can take several hundreds of milliseconds up to a few seconds depending on the configuration of the routing protocol. For his PhD thesis, Pierre Francois studied this problem in details. He first designed a simulator to analyse all the factors that influence the convergence time in a large ISP network. This analysis revealed that it is difficult for a large network to converge within less than 100-200 milliseconds after a topology change. During this period, transient loops can happen and packets get loss even for planned and non-urgent topology changes. Pierre Francois designed several techniques to avoid these transient loops during the convergence of a link-state routing protocol. The first solution required changes to the link-state routing protocol. We thought that getting IETF consensus on this solution would be very difficult. We were right since the framework draft has still not yet been adopted.
At INFOCOM 2007, by refining an intuition proposed by Mike Shand, we proposed a solution that does not require standardisation. This solution relies on the fact that if the weight of a link is changed by one (increase or decrease), no transient loop can happen. However, using only unit weight changes is not practical given the wide range of weights in real networks. Fortunately, our paper showed that when shutting down a link (i.e. setting its weight to infinity), it is possible to use a small number of metric increments to safely perform the reconfiguration. This metric reconfiguration was well accepted by the research community and received the INFOCOM 2007 best paper award.
The algorithms proposed in our INFOCOM 2007 paper were implemented in Java and took a few seconds or more to run. It was possible to run them on a management platform, but not on a router. Two years ago, Pascal Merindol and Francois Clad reconsidered the problem. They found new ways of expressing the proofs that enable loop-free reconfiguration of link-state protocols upon topology changes. Furthermore, they have also significantly improved the performance of the algorithms proposed in 2007 and reimplemented everything in C. The new algorithms operate one order of magnitude faster than the 2007 version. It becomes now possible to implement them directly on routers to enable OSPF and IS-IS to avoid low transient loops when dealing with non-urgent topology changes.
All the details are provided in our forthcoming paper that will appear in IEEE/ACM Transactions on Networking.
Hash functions are not the only answer to load balancing problems
Load balancing is important in many networks because it allows to spread the load over different ressources. Load balancing can happen at different layers of the protocol stack. A web server farm uses load balancing to distribute the load between different servers. Routers rely on Equal Cost Multipath (ECMP) to balance packets without breaking TCP flows. Bonding enables to combine several links in the datalink layer.
Many deployments of load balancing rely on the utilisation of hash functions. ECMP is a typical example. When a router has several equal cost paths towards the same destination, it can use a hash function to distribute the packets over these paths. Typically, the router would compute for each packet to be forwarded hash(IPsrc, IPdst, Portsrc, Portdst) mod N where N is the number of equal cost paths towards the destination to select the nexthop. Various hash functions have been evaluated in the literature RFC 2992 : CRC, checksum, MD5, … Many load balancing techniques have adopted hash functions because they can be efficiently computed. An important criteria in selecting a function to perform load balancing is whether a small change in its input gives a large change in its output. This is sometimes called the avalanche effect and is a requirement for strong hash functions used in crypto applications. Unfortunately, hash functions have one important drawback : it is very difficult to predict an input that would lead to a given output. For crypto applications, this is the expectation, but many load balancing applications would like to be able to predict the output of the load balancing function while still benefitting from the avalanche effect.
In a recent paper, we have shown that it is possible to design a load balancing technique that both provides the avalanche effect (which is key for a good balancing of the traffic) and is predictable. The intuition behind this idea is that the hash function can be replaced by a block cipher. Block ciphers are usually used to encrypt/decrypt information by using a secret key. Since they are designed to provide an output that appears as random as possible for a wide range of inputs, they also exhibit the avalanche effect. Furthermore, provided that the key is known, the input that leads to a given output can be easily predicted. Our paper provides all the details and shows the benefits that such a technique can provide with Multipath TCP in datacenter networks, but there are many other potential applications.
Humming in the classroom
One of the challenges of teaching to large classes is to encourage the students to interact during the class. Today’s professors do not simply read their course to passive students. Most try to initiate interaction with the students by asking questions, polling the students opinions, … However, my experience in asking questions to students in a large class shows that it is difficult to get answers from many students. Asking the students to raise their hands to vote for a binary question almost always results in : - a small fraction of the students vote for the correct answer - a (usually smaller) fraction of the students vote for the wrong answer - most of the students do not vote
One of the reasons why students do not vote is that they are unsure about their answer and do not want their colleagues or worse their professor to notice that they had the wrong answer. Unfortunately, this decreases the engagement of the students and after some time some of them do not even think about the questions that are asked.
To cope with those shy students, I’ve started to ask them to hum to answer some of my questions. Humming is a technique that is used by the IETF to evaluate consensus during a working group meeting. The IETF develops the specifications for most of the protocols that are used on the Internet. An IETF working group is responsible for a given protocol. IETF participants meet every quarter together. During these meetings, engineers and protocol experts discuss about the new protocol specifications being developed. From time to time, working group chairs need to evaluate whether the working group agrees with one proposal. This question can be discussed on the working group’s mailing list. Another possibility would be to use a show of hands during the meeting, but during a show of hands, it is possible to recognize who is in favor and who is against a given proposal. This is not always desirable. The IETF uses a nice trick to solve this problem. Instead of asking participants to raise their hands, working group chairmans ask participants to hum. If most of the participants in the room hum, the noise level is high and the vote is accepted. Otherwise, if the noise level is similar in favor and against a proposal, then there is no consensus and the proposal will need to be discussed at another meeting later.
Humming works well in the classroom as well when asking a binary question or a question having a small number of possible answers. Students can give their opinion without revealing it to the professor. Of course, electronic voting systems can be used to preserve the anonymity of students, but deploying these systems in large classes is more and costly and more time consuming than humming…
References
- Hoffman, The Tao of IETF, http://www.ietf.org/tao.html
- Tomas Carlsson, The Unique Political Soul of the IETF, IETF Journal December 2007
Looking at the DNS through a looking glass
In the networking community a looking glass is often a router located inside an ISP network that can be contacted openly via a telnet server or sometimes an HTTP server. These looking glasses are very useful to debug networking problems since they can be used to detect filtering of BGP routes or other problems.
A nice example of these looking glasses is the web server maintained by GEANT the pan-European research network. The GEANT looking glass provides dumps of BGP routing tables, traceroutes and other tools from most routers of GEANT. As an example, GEANT routers have three routes towards network 8.8.8.0/24 that includes the open DNS resolver managed by google.
inet.0: 433796 destinations, 1721271 routes (433773 active, 12 holddown, 755 hidden)
+ = Active Route, - = Last Active, * = Both
8.8.8.0/24 *[BGP/170] 3w6d 01:51:39, MED 0, localpref 95
AS path: 15169 I
> to 62.40.125.202 via xe-4/1/0.0
[BGP/170] 20w6d 03:35:32, MED 0, localpref 80
AS path: 3356 15169 I
> to 212.162.4.9 via xe-2/1/0.0
[BGP/170] 4w5d 04:06:28, MED 0, localpref 80
AS path: 174 15169 I
> to 149.6.42.73 via ge-6/1/0.0
As on all BGP routers, the best path which is actually used to forward packets is prefixed by *. Network operators have deployed many looking glasses, a list can be found on http://www.lookinglass.org/ and www.traceroute.org among others.
The correction operation of today’s Internet does not only depend on the propagation of BGP prefixes. Another frequent issue today is the correct dissemination of DNS names. In the early days, command-line tools like nslookup and dig were sufficient to detect most DNS problems. Today, this is not always the case anymore since Content Distribution Networks provide different DNS answers to the same DNS request coming from different clients. Furthermore, some network operators use DNS resolvers that sometimes provide invalid answers to some DNS requests. Some of these DNS resolvers are deployed due to legal constraints as some countries block Internet access to some sites. However, some ISPs have sometimes less legal reasons to deploy fake DNS resolvers as shown recently in France where Free deployed DNS masquerading to block access to some Internet advertisement companies. Checking the correct distribution of DNS names becomes now an operational problem. Several authors have proposed tools to examine the answers provided by the DNS to remote clients. Stéphane Bortzmeyer, who has sent many patches and improvements for the CNP3, book has developed a very interesting alternative to these DNS looking glasses. dns-lg can be used manually through a web server, but can also be used through an API that provides JSON output. This is pretty interesting to develop automated tests. An interesting feature of dns-lg is its REST API that allows to easily query the looking glass. For example, http://dns.bortzmeyer.org/multipath-tcp.org/NS returns the NS record for multipath-tcp.org while http://dns.bortzmeyer.org/www.uclouvain.be/AAAA returns the IPv6 address (AAAA) record of UCL’s web server. Thanks to its web interface, dns-lg could be a very nice alternative for students who have difficulties to use classical command line tools when they start learning networking.
A closer look at broadband and cellular performance
The Internet started almost exactly 30 years ago when ARPANet switched to the TCP/IP protocol suite. At that time, only a few experimental hosts were connected to the network. Three decades later, the Internet is part of our lives and most users access the Internet by using broadband access or cellular networks. Understanding the performance characteristics of these networks is essential to understand the factors that influence Internet protocols.
In 2011, Srikanth Sundaresan and several other researchers presented a very interesting paper [SdDF+11] at SIGCOMM that analysed a large number of measurement studies conducted by using modified home access routers. Two types of devices were used : dozen of home routers modified by the Bismark project and several thousands of measurement boxes deployed by Samknows throughout the US. This paper revealed that there is a huge diversity in broadband performance in the US. This diversity depends on the chosen ISP, the chosen plan and also the geographical location. The paper was later revised and published in Communications of the ACM, ACM’s flagship magazine [SdDF+12].
During the last edition of the Internet Measurements Conference, Joel Somers, Paul Barford and Igor Canadi presented two papers that analyse Internet performance from a different viewpoint. [CBS12] uses data from http://www.speedtest.net and SamKnows to analyse broadband performance. This enables them to provide a much more global analysis of broadband performance. For example, the figure below shows the average download throughput measured in different countries.
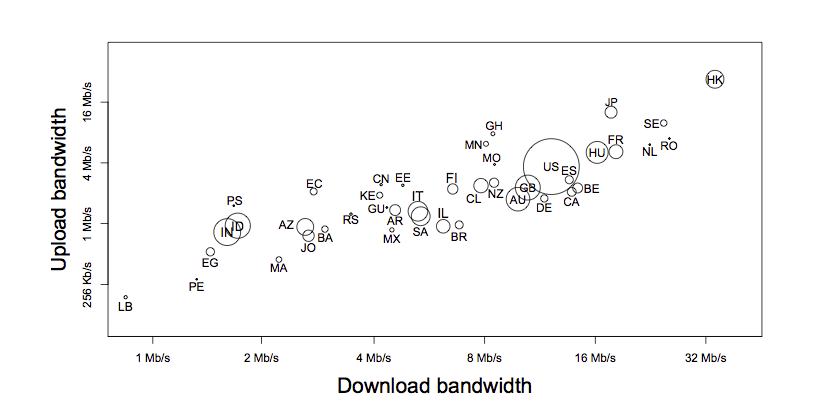
Average download performance (source [CBS12])
The second paper, [SB12] explores the performance of WiFi and cellular data networks in more than a dozen of cities, including Brussels. Latency and bandwidth information is extracted from http://www.speedtest.net. A first point to be noted from these measurements is that cellular and WiFi performance are significantly lower than broadband performance, despite all the efforts in deploying higher speed wireless networks. Note that the data was collected in February-June 2011, the network performance might have changed since. When comparing WiFi and cellular data, WiFi is consistently faster in all studied regions. In Brussels for example, WiFi download throughput is 8.6 Mbps in Brussels while the average cellular download throughput is only 1.2Mbps. Latency is also an important performance factor. In Brussels, the average WiFi latency is slightly above 100 milliseconds while it reaches 281 milliseconds for cellular networks. Both papers are recommended readings for anyone willing to better understand the performance of Internet access networks.
| [CBS12] | (1, 2) Igor Canadi, Paul Barford, and Joel Sommers. Revisiting Broadband Performance. In the 2012 Internet Measurements conference, 273–286. New York, New York, USA, 2012. ACM Press. |
| [SB12] | Joel Sommers and Paul Barford. Cell vs. WiFi : On the Performance of Metro Area Mobile Connections. In the 2012 Internet Measurements conference, 301. New York, New York, USA, 2012. ACM Press. |
| [SdDF+11] | S Sundaresan, W de Donato, N Feamster, Renata Teixeira, Sam Crawford, and Antonio Pescapè. Broadband internet performance: a view from the gateway. SIGCOMM, 2011. |
| [SdDF+12] | Srikanth Sundaresan, Walter de Donato, Nick Feamster, Renata Teixeira, Sam Crawford, and Antonio Pescapè. Measuring home broadband performance. ACM SIGCOMM Computer Communication Review, 55(11):100, November 2012. |
REconfiguration matters
Network configuration and management is an important problem for all network operators. IP networks are implemented by using a large number of switches and routers from different vendors. All these devices must be configured by the operators to maximise the performance of the network. In some networks, configuration files contain several tens of thousands of lines per device. Managing all these configurations is costly in large networks. Some researchers have worked on analysing the complexity of these networks and proposing abstractions to allow operators to better configure their network. Still, network configuration and management is often closer to an art than to science.
Researchers often consider the network configuration problem as a design problem. Starting from a blank sheet, how can a network operator define his/her objectives and then derive the configuration files that meet these objectives. This is not how networks are operated. Network operators almost never have the opportunity to design and configure a network from scratch. This only happens in new datacenters or new entreprise networks. In their recent work, Laurent Vanbever, Stefano Vissicchio and other colleagues have addressed a slightly different but much more relevant problem : network REconfiguration. There are only two letters of difference between network configuration and network REconfiguration, but these two letters reflect one of the important sources of complexity in managing a network and introducting new services. Once a network has been configured, it must remain in operation 24h per day, 365 days per year. Network equipment can remain in operation for 5-10 years and during their period their role in the network changes. All these changes must be done with as few impact as possible on the network.
To better understand the difficulty of reconfiguring a network, it is interesting to have a brief look at earlier papers that deal with similar problems. A decade ago, routing sessions had to be reset for each policy change or when the operating system of the router had to be upgraded. Aman Shaikh and others have shown that it is possible to update the control plane of a router without disrupting the dataplane [SDV06]. Various graceful shutdown and graceful restart techniques have been proposed and implemented for the major control plane protocols. Another simple example of a reconfiguration problem is when operators need to change the OSPF weight associated to one link. This can happen for traffic engineering or maintenance purposes. This change triggers an OSPF convergence than can cause transient loops. Pierre Francois and others have proposed techniques that allow these simple reconfigurations to occur without causing transient forwarding problems [FB07][FSB07]. Another step to aid network reconfiguration was the shadow configuration paper [AWY08] that shows how to run different configurations in the same network at a given time.
During the last years, several network Reconfiguration problems have been addressed. The first problem is the migration from one configuration of a link-state routing protocol (e.g. OSPF without areas) to another link-state routing protocol (e.g. IS-IS with areas). At first glance, this problem could appear to be simple. However, network operators who have performed such a transition have spent more than half a year to plan the transition and analyse all the problems that could occur. [VVP+11] provides first a theoretical framework that shows the problems that could occur during such a reconfiguration. It shows that it is possible to avoid transient forwarding problems during the reconfiguration by using a ships-in-the night approach and updating the configuration of the routers in a specific order. Unfortunately, finding this ordering is an NP-complete problem. However, the paper proposes heuristics that find a suitable ordering and applies it to real networks and provides measurements from a prototype reconfigurator that manages an emulated network.
A second problem are the BGP reconfigurations. Given the complexity of BGP, it is not surprising that BGP reconfigurations are more difficult than IGP reconfigurations. [VCVB12] first shows that signalling and forwarding correctness that are usually used to very iBGP configuration are not sufficient properties. Dissemination correctness must be ensured in addition to these two properties. :cite:`6327628`_ analyses several iBGP reconfiguration problems and identifies some problematic configurations. To allow an iBGP reconfiguration, this paper proposes and evaluates a BGP multiplexer that combined with encapsulation enables iBGP reconfigurations. The proposed solution provably enables lossless BGP reconfigurations by leveraging existing technology to run multiple isolated control-planes in parallel.
This work on REconfiguration has already lead up to some follow-up work. For example, [RFR+12] has proposed techniques that use tagging to allow software-defined networks to support migrations in a seamless manner. We can expect to rad more papers that deal with REconfiguration problems in the coming years.
| [AWY08] | Richard Alimi, Ye Wang, and Y. Richard Yang. Shadow configuration as a network management primitive. SIGCOMM Comput. Commun. Rev., 38(4):111–122, August 2008. URL: http://doi.acm.org/10.1145/1402946.1402972, doi:10.1145/1402946.1402972. |
| [FSB07] | P. Francois, M. Shand, and O. Bonaventure. Disruption free topology reconfiguration in ospf networks. In INFOCOM 2007. 26th IEEE International Conference on Computer Communications. IEEE, volume, 89 –97. may 2007. URL: http://inl.info.ucl.ac.be/publications/disruption-free-topology-reconfigurat, doi:10.1109/INFCOM.2007.19. |
| [FB07] | Pierre Francois and Olivier Bonaventure. Avoiding transient loops during the convergence of link-state routing protocols. IEEE/ACM Trans. Netw., 15(6):1280–1292, December 2007. URL: http://inl.info.ucl.ac.be/publications/avoiding-transient-loops-during-conve, doi:10.1109/TNET.2007.902686. |
| [RFR+12] | Mark Reitblatt, Nate Foster, Jennifer Rexford, Cole Schlesinger, and David Walker. Abstractions for network update. In Proceedings of the ACM SIGCOMM 2012 conference on Applications, technologies, architectures, and protocols for computer communication, SIGCOMM ‘12, 323–334. New York, NY, USA, 2012. ACM. URL: http://doi.acm.org/10.1145/2342356.2342427, doi:10.1145/2342356.2342427. |
| [SDV06] | Aman Shaikh, Rohit Dube, and Anujan Varma. Avoiding instability during graceful shutdown of multiple ospf routers. IEEE/ACM Trans. Netw., 14(3):532–542, June 2006. URL: http://dx.doi.org/10.1109/TNET.2006.876152, doi:10.1109/TNET.2006.876152. |
| [VVP+11] | Laurent Vanbever, Stefano Vissicchio, Cristel Pelsser, Pierre Francois, and Olivier Bonaventure. Seamless network-wide igp migrations. In Proceedings of the ACM SIGCOMM 2011 conference, SIGCOMM ‘11, 314–325. New York, NY, USA, 2011. ACM. URL: http://inl.info.ucl.ac.be/publications/seamless-network-wide-igp-migrations, doi:10.1145/2018436.2018473. |
| [VCVB12] | S. Vissicchio, L. Cittadini, L. Vanbever, and O. Bonaventure. Ibgp deceptions: more sessions, fewer routes. In INFOCOM, 2012 Proceedings IEEE, volume, 2122 –2130. march 2012. URL: http://inl.info.ucl.ac.be/publications/ibgp-deceptions-more-sessions-fewer-routes, doi:10.1109/INFCOM.2012.6195595. |
Mininet : improving the reproducibility of networking research
In most research communities, the ability to reproduce research results is a key step in validating and accepting new research results. Ideally, all published papers should contain enough information to enable researchers to reproduce the results discussed in the paper. Reproducibility is relatively easy for theoretical or mathematically oriented papers. If the main contribution of the paper is a proof or a mathematical model, then the paper contains all the information about the results. If the paper is more experimental, then reproducibility of often a concern. There are many (sometimes valid) reasons that can explain why the results obtained by the paper are difficult to reproduce :
- the paper contains measurement data that are proprietary. This argument is often used by researchers who have tested their new solution in a commercial network, datacenter or used measurement data such as packet traces whose publication could revela private information
- the source code used for the paper is proprietary and cannot be released to other researchers. This argument is weaker, especially when researchers extend publicly available (and often open-source) software to perform their research. Although they have benefitted from the publicly available software, they do not release their modification to this software
During the Conext2012, Brandon Heller, Nikhil Handigol, Vimalkumar Jeyakumar, Bob Lantz and Nick McKeown have presented a container-based emulation technique called Mininet 2.0 that enables researchers to easily create reproducible experiments. The paper describes in details the extension that they have developed above the Linux kernel to be able to emulate efficiently a set of hosts interconnected by virtual links on a single Linux kernel. The performance that they obtained is impressive. More importantly, they explain how they were able to reproduce recent networking papers on top of Mininet. Instead of performing the experiments themselves, they used Mininet 2.0 for a seminar at Stanford University and 17 groups of students were able to reproduce various measurements by using one virtual machine on EC2.
Beyond proposing a new tool, they also propose a new way to submit papers. In the introduction, they note :
To demonstrate that network systems research can indeed be made repeatable, each result described in this paper can be repeated by running a single script on an Amazon EC2 [5] instance or on a physical server. Following Claerbout’s model, clicking on each figure in the PDF (when viewed electronically) links to instructions to replicate the experiment that generated the figure. We encourage you to put this paper to the test and replicate its results for yourself.
I sincerely hope that will see more directly reproducible experimental papers in the coming months and years in the main networking conferences.
Brandon Heller, Nikhil Handigol, Vimalkumar Jeyakumar, Bob Lantz, Nick McKeown, Reproducible Network Experiments using Container Based Emulation, Proc. Conext 2012, December 2012, Nice, France
A real use case for the Locator/Identifier Separation Protocol
The Locator/Identifier Separation Protocol (LISP) was designed several years ago by Dino Farinacci and his colleagues at Cisco Systems as an architecture to improve the scalability of the Internet routing system. Like several other such proposals, LISP proposed to separate the two usages of addresses. In contrast with many other proposals that were discussed in the IRTF Routing Research Group, LISP has been fully implemented at tested on the global Internet through the lisp4.net testbed. Several implementations of LISP exist on different types of Cisco routers and there is also the OpenLISP open-source implementation on FreeBSD [ISB11].
On the Internet, IP addresses are used for identifying an endhost (or more precisely an interface on such a host) where TCP connections can be terminated. Addresses are also used as locators to indicate to the routing system the location of each router and endpoint. On the Internet, both endpoint addresses and locators are advertised in the routing system and contribute to its growth. With LISP, there are two types of addresses :
- locators. These addresses are used to identify routers inside the network. The locators are advertised in the routing system.
- identifier addresses are used to identify endhosts. These addresses are not distributed in the routing system. This is the main advantage of LISP from a scalability viewpoint.
A typical deployment of LISP in the global Internet is described in the figure below [SIBF12].
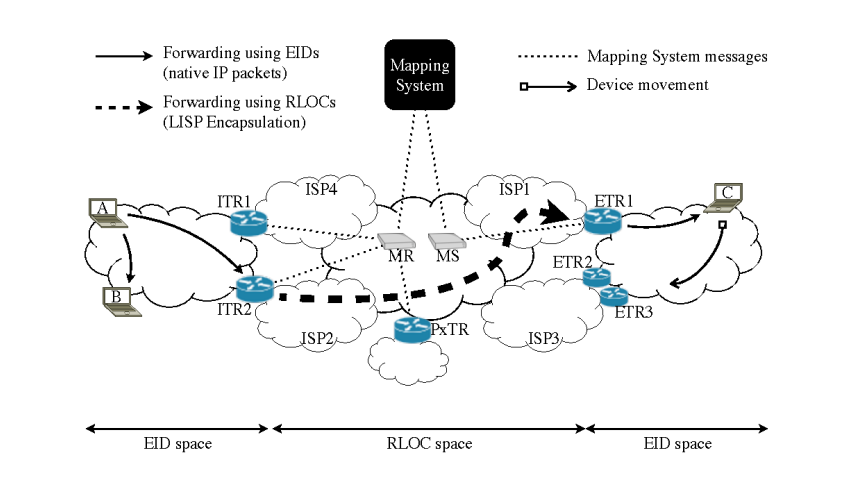
LISP packet flow (source [SIBF12])
Endhosts are assigned identifiers. Identifiers are IP addresses (IPv4 or IPv6) whose reachability is advertised by the intradomain routing protocol inside the enterprise network. Two hosts that belong to the same network can exchange packets directly (A->B arrow in the above figure). Locators are assigned to border routers (ITRx and ETRx in the figure above). These locators are advertised in the global Internet routing system by using BGP. As the addresses of hosts A, B and C are not advertised by BGP, packets destined to these addresses cannot apear in the global Internet. LISP solves this problem by using map-and-encap. When A sends a packet towards C, it first sends a regular packet to its border router (ITR2 in the above figure). The border router performs two operations. First, it queries the LISP mapping system to retrieve the locator of the border routers that can reach the destination identifier C. Then, the original packet destined to C in encapsulated inside a LISP packet whose source is ITR2 and destination ETR1, one of the locators of identifier C. When ETR1 receives the encapsulated packet, it removes the first IP header and forwards as a regular IP packet towards its destination.
The mapping system plays an important role in the performance and the stability of a LISP-based network since border routers need to maintain a cache of the mappings that they use [IB07]. The first releases of LISP used a hack that combined GRE tunnels and BGP to distribute mapping information [FFML11]. This solution had the advantage of being simple to implement (at least on Cisco routers) but we expected that it would become complex to operate and maintain in the long term. After many discussions and simulations, we convinced the LISP designers to opt for a different mapping system whose operation is inspired by the Domain Name System. Our LISP-TREE proposal [JCAC+10] is the basis for the DDT mapping system that is now implemented and used by LISP routers.
Simulation-based studies have shown that LISP can provide several important benefits compared to the classic Internet architecture [QIdLB07]. Some companies have used LISP to support specific services. For example, facebook has relied on LISP to support IPv6-based services [SIBF12]. However, until now the deployment use cases were not completely convincing from a commercial viewpoint. A recent announcement could change the situation. In a whitepaper, Cisco describes how LISP can be combined with encryption techniques to support Virtual Private Network services. Given the importance of VPN services for enterprise networks, this could become a killer application for LISP. There are apparently already several networks using LISP to support VPN services. The future of LISP will be guaranteed once a second major router vendor decides to implement LISP.
| [FFML11] | V. Fuller, D. Farinacci, D. Meyer, and D. Lewis. Lisp alternative topology (lisp+alt). Internet draft, draft-ietf-lisp-alt-10.txt, December 2011. |
| [IB07] | Luigi Iannone and Olivier Bonaventure. On the cost of caching locator/ID mappings. In CoNEXT ‘07: Proceedings of the 2007 ACM CoNEXT conference. ACM, December 2007. |
| [ISB11] | Luigi Iannone, Damien Saucez, and Olivier Bonaventure. Implementing the Locator/ID Separation Protocol: Design and experience. Computer Networks: The International Journal of Computer and Telecommunications Networking, March 2011. |
| [JCAC+10] | Loránd Jakab, Albert Cabellos-Aparicio, Florin Coras, Damien Saucez, and Olivier Bonaventure. LISP-TREE: a DNS hierarchy to support the lisp mapping system. IEEE Journal on Selected Areas in Communications, October 2010. |
| [QIdLB07] | Bruno Quoitin, Luigi Iannone, Cédric de Launois, and Olivier Bonaventure. Evaluating the benefits of the locator/identifier separation. In MobiArch ‘07: Proceedings of 2nd ACM/IEEE international workshop on Mobility in the evolving internet architecture. ACM Request Permissions, August 2007. |
| [SIBF12] | (1, 2, 3) Damien Saucez, Luigi Iannone, Olivier Bonaventure, and Dino Farinacci. Designing a Deployable Internet: The Locator/Identifier Separation Protocol. IEEE Internet Computing Magazine, 16(6):14–21, 2012. |
TCP congestion control schemes
Since the publication of two end-to-end congestion control schemes at SIGCOMM’88 [Jac88] [RJ88], congestion control has been a very popular and important topic in the scientific community. The IETF tried to mandate a standard TCP congestion control scheme that would be used by all TCP implementations RFC 5681, but today’s TCP implementations contain different congestions control schemes. Linux supports different congestion control schemes that can be configured by the system administrator. A detailed analysis of these implementations was presented recently in [CGPP12] Windows has opted for their own congestion control scheme that is included in the microsoft stack.
Given the importance of the congestion control scheme from a performance viewpoint, it is useful to have a detailed overview of the different congestion control schemes that have been proposed and evaluated. The best survey paper on TCP congestion control is probably the paper written by Alexander Afanasyev and his colleagues on Host-to-Host Congestion Control for TCP [ATRK10] and that appeared in IEEE Communications Surveys and tutorials. This paper provides a detailed overview of the different TCP congestion control schemes and classifies them.
Last week, I received an alert from google scholar indicating that a new survey on TCP congestion control appeared in the Journal of Network and Computer Applications. This paper tries to provide a classification of the different TCP congestion control schemes. Unfortunately, the paper is not convincing at all and furthermore it reuses two of the figures published in [ATRK10] without citing this previously published survey. This is a form of plagiarism that should have been detected by the editors of the Journal of Network and Computer Applications
| [ATRK10] | (1, 2) Alexander Afanasyev, Neil Tilley, Peter Reiher, and Leonard Kleinrock. Host-to-Host Congestion Control for TCP. IEEE Communications Surveys & Tutorials, 12(3):304–342, 2010. |
| [CGPP12] | C Callegari, S Giordano, M Pagano, and T Pepe. Behavior analysis of TCP Linux variants. Computer Networks, 56(1):462–476, January 2012. |
| [Jac88] | V. Jacobson. Congestion avoidance and control. In ACM SIGCOMM Computer Communication Review, volume 18, 314–329. ACM, 1988. |
| [RJ88] | KK Ramakrishnan and R. Jain. A binary feedback scheme for congestion avoidance in computer networks with a connectionless network layer. In ACM SIGCOMM Computer Communication Review, volume 18, 303–313. ACM, 1988. |