Evolution of link bandwidths
During my first lesson for the undergrad networking class, I wanted to provide the students with some historical background of the evolution of link bandwidth. Fortunately, wikipedia provides a very interesting page that lists most of the standards for modems, optical fibers, …
A first interesting plot is the evolution of the modems that allow to transmit data over the traditional telephone network. The figure below, based on information extracted from http://en.m.wikipedia.org/wiki/List_of_device_bandwidths shows the evolution of the modem technology. The first method to transfer data was the Morse code that appeared in the mid 1800s. After that, it took more than a century to move to the Bell 101 modem that was capable of transmitting data at 110 bits/sec. Slowly, 300 bps and later 1200 bps modems appeared. The late 1980s marked the arrival of faster modems with 9.6 kbps and later 28.8 and 56 kbps. This marked the highest bandwidth that was feasible on a traditional phone line. ISDN appeared in the late 1980s with a bandwidth of 64 kbps on digital lines that was later doubled.
When the telephone network become the bottleneck, telecommunication manufacturers and network operators moved to various types of Digital Subscriber Lines technologies, ADSL being the most widespread. From the early days at 1.5 Mbps downstream to the latests VDSL deployments, bandwidth has increased by almost two order of magnitude. As of this writing, it seems that xDSL technology is reaching its limits and while bandwidth will continue to grow, the rate of improvement will not remain as high as in the past. In parallel, CATV operators have deployed various versions of the DOCSIS standards to provide data services in cable networks. The next step is probably to go to fiber-based solutions, but they cost more than one order of magnitude more than DSL services and can be difficult to deploy in rural areas.
The performance of wireless networks has also significantly improved. As an illustration, and again based on data from http://en.m.wikipedia.org/wiki/List_of_device_bandwidths here is the theoretical maximum bandwidth for the various WiFi standards. From 2 Mbps for 802.11 in 1997, bandwidth increased to 54 Mbps in 2003 for 802.11g and 600 Mbps for 802.11n in 2009.
The datasets used in this post are partial. Suggestions for additional datasets that could be used to provide a more detailed view of the evolution of bandwidth are more than welcome. For optical fiber, an interesting figure appeared in Nature, see http://www.nature.com/nphoton/journal/v7/n5/fig_tab/nphoton.2013.94_F1.html
Flipping an advanced networking course
Before the beginning of the semester, Nick Feamster informed me that he decided to flip his advanced networking course . Various teachers have opted for flipped classrooms to increase the interaction with students. Instead of using class time to present theory, the teacher focuses his/her attention during the class on solving problems with the students. Various organisations of a flipped classroom have been tested. Often, the teacher posts short videos that explain the basic principles before the class and the students have to listen to the videos before attending the class. This is partially the approach adopted by Nick Feamster for his class.
By bringing more interaction in the classroom, the flipped approach is often considered to be more interesting for the teacher as well as for the student. Since my advanced networking class gathers only a few tens of students, compared to the 100+ and 300+ students of the other courses that I teach, I also decided to flip one course this year.
The advanced networking course is a follow-up to the basic networking course. I cover several advanced topics and aims at explaining to the students the operation of large Internet Service Provider networks. The main topics covered are :
- Interdomain routing with BGP (route reflectors, traffic engineering, …)
- Traffic control and Quality of Service (from basic mechanisms - shaping, policing, scheduling, buffer acceptance - to services - integrated or differentiated services)
- IP Multicast and Multicast routing protocols
- Multiprotocol Label Switching
- Virtual Private Networks
- Middleboxes
The course is complemented by projects during which the students configure and test realistic networks built from Linux-based routers.
During the last decade, I’ve taught this course by using slides and presenting them to the students and discussing the theoretical material. I could have used some of them to record videos explaining the basic principles, but I’m still not convinced by the benefits of using video online as a learning vehicle. Video is nice for demonstrations and short introductory material, but students need written material to understand the details. For this reason, I’ve decided to opt for a seminar-type approach where the students read one or two articles every week to understand the basic principles. Then, the class focuses on discussing real cases or exercises.
Many courses are organized as seminars during which the students read recent articles and discuss them. Often, these are advanced courses and the graduate students read and comment recent scientific articles. This approach was not applicable in many case given the maturity of the students who follow the advanced networking course. Instead of using purely scientific articles, I’ve opted for tutorial articles that appear in magazines such as IEEE Communications Magazine or the Internet Protocol Journal . These articles are easier to read by the students and often provide good tutorial content with references that the students can exploit if they need additional information.
The course has started a few weeks ago and the interaction with the student has been really nice. I’ll regularly post updates on the articles that I’ve used, the exercises that have been developed and the student’s reactions. Comments are, of course, welcome.
Happy eyeballs makes me unhappy…
Happy eyeballs, defined in RFC 6555, is a technique that enables dual-stack hosts to automatically select between IPv6 and IPv4 based on their respective performance. When a dual-stack host tries to contact a webserver that is reachable over both IPv6 and IPv4, it :
- first tries to establish a TCP connection towards the IPv6 or IPv4 address and starts a short timeout, say 300 msec
- if the connection is established over the chosen address family, it continues
- if the timer expires before the establishment of the connection, a second connection is tried with the other address family
Happy eyeballs works well when the one of the two address families provides bad performance or is broken. In this case, a host using happy eyeballs will automatically avoid the broken address family. However, when both IPv6 and IPv4 work correctly, happy eyeballs may cause frequent switches between the two address families.
As an exemple, here is a summary of a packet trace that I collected when contacting a dual-stack web server from my laptop using the latest version of MacOS.
First connection
09:40:47.504618 IP6 client6.65148 > server6.80: Flags [S], cksum 0xe3c1 (correct), seq 2500114810, win 65535, options [mss 1440,nop,wscale 4,nop,nop,TS val 1009628701 ecr 0,sackOK,eol], length 0
09:40:47.505886 IP6 server6.80 > client6.65148: Flags [S.], cksum 0x1abd (correct), seq 193439890, ack 2500114811, win 14280, options [mss 1440,sackOK,TS val 229630052 ecr 1009628701,nop,wscale 7], length 0
The interesting information in these packets are the TCP timestamps. Defined in RFC 1323, these timestamps are extracted from a local clock. The server returns its current timestamp in the SYN+ACK segment.
Thanks to happy eyeballs, the next TCP connection is sent over IPv4 (it might be faster than IPv6, who knows). IPv4 works well and answers immediately
09:40:49.512112 IP client4.65149 > server4.80: Flags [S], cksum 0xee77 (incorrect -> 0xb4bd), seq 321947613, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1009630706 ecr 0,sackOK,eol], length 0
09:40:49.513399 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF], proto TCP (6), length 60) server4.80 > client4.65149: Flags [S.], cksum 0xd86f (correct), seq 873275860, ack 321947614, win 5792, options [mss 1380,sackOK,TS val 585326122 ecr 1009630706,nop,wscale 7], length 0
Note the TS val in the returning SYN+ACK. The value over IPv4 is much larger than over IPv6. This is not because IPv6 is faster than IPv4, but indicates that there is a load-balancer that balances the TCP connections between (at least) two different servers.
Shortly after, I authenticated myself over an SSL connection that was established over IPv4
09:41:26.566362 IP client4.65152 > server4.443: Flags [S], cksum 0xee77 (incorrect -> 0x420d), seq 3856569828, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1009667710 ecr 0,sackOK,eol], length 0
09:41:26.567586 IP server4.443 > client4.65152: Flags [S.], cksum 0x933e (correct), seq 3461360247, ack 3856569829, win 14480, options [mss 1380,sackOK,TS val 229212430 ecr 1009667710,nop,wscale 7], length 0
Again, a closer look at the TCP timestamps reveals that there is a third server that terminated the TCP connection. Apparently, in this case this was the load-balancer itself that forwarded the data extracted from the connection to one of the server.
Thanks to happy eyeballs, my TCP connections reach different servers behind the load-balancer. This is annoying because the web servers maintain one session and every time I switch from one session to another I might switch from one server to another. In my experience, this happens randomly with this server, possibly as a function of the IP addresses that I’m using and the server load. As a user, I experience difficulties to log on the server or random logouts, while the problem lies in unexpected interactions between happy eyeballs and a load balancer. The load balancer would like to stick all the TCP connections from one host to the same server, but due to the frequent switchovers between IPv6 and IPv4 it cannot stick each client to a server.
I’d be interested in any suggestions on how to improve this load balancing scheme without changing the web servers…
Sandstorm : even faster TCP
Researchers have worked on improving the performance of TCP since the early 1980s. At that time, many researchers considered that achieving high performance with a software-based TCP implementation was impossible. Several new transport protocols were designed at that time such as XTP. Some researchers even explored the possibility of implementing transport protocols. Hardware-based implementations are usually interesting to achieve high performance, but they are usually too inflexible for a transport protocol. In parallel with this effort, some researchers continued to believe in TCP. Dave Clark and his colleagues demonstrated in [1] that TCP stacks could be optimized to achieve high performance.
TCP implementations continued to evolve in order to achieve even higher performance. The early 2000s, with the advent of Gigabit interfaces showed a better coupling between TCP and the hardware on the network interface. Many high-speed network interfaces can compute the TCP checksum in hardware, which reduces the load on the main CPU. Furthermore, high-speed interfaces often support large segment offload. A naive implementation of a TCP/IP stack would be to send segments and acknowledgements independently. For each segment sent/received, such a stack could need to process one interrupt, a very costly operation on current hardware. Large segment offload provides an alternative by exposing to the TCP/IP stack a large segment size, up to 64 KBytes. By sending an receiving larger segments, the TCP/IP stack minimizes the cost of processing the interrupts and thus maximises its performance.
Broadband in Europe
The European Commission has published recently an interesting survey of the deployment of broadband access technologies in Europe. The analysis is part of the Commission’s Digital Agenda that aims at enabling home users to have speeds of 30 Mbps or more. Technologies like ADSL and cable modems are widely deployed in Europe and more than 95% of European households can subscribe to fixed broadband networks.
The report provides lots of data about the different technologies and countries. Some of the figures are worth being highlighted. A first interesting figure is the distribution of the different advanced access technologies. Satellite is widely available given its large footprint. DSL is also widely available, but less in rural areas. The newer technologies like VDSL, FTTP, WiMAX, LTE and DOCSIS3 cable start to appear.
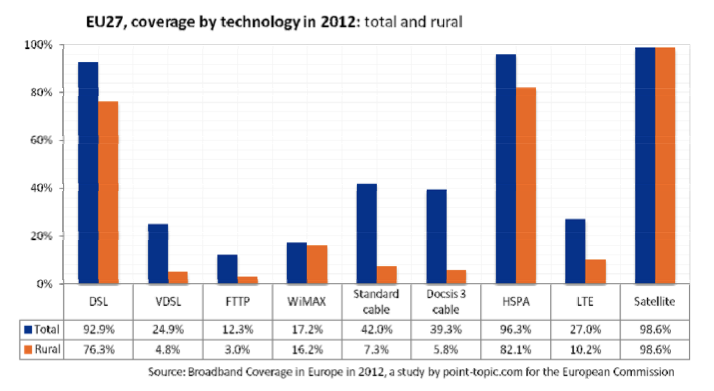
Broadband coverage in Europe, source Study on broadband coverage 2012
For the standard fixed broadband network technologies, the top three in terms of coverage is Netherlands, Malta and Belgium. It remains simpler to largely deploy broadband in small countries. For the next generation broadband access, the same three countries remain at the top except that Malta has better coverage than the Netherlands. For rural regions, Luxemburg is the best country in terms of coverage.
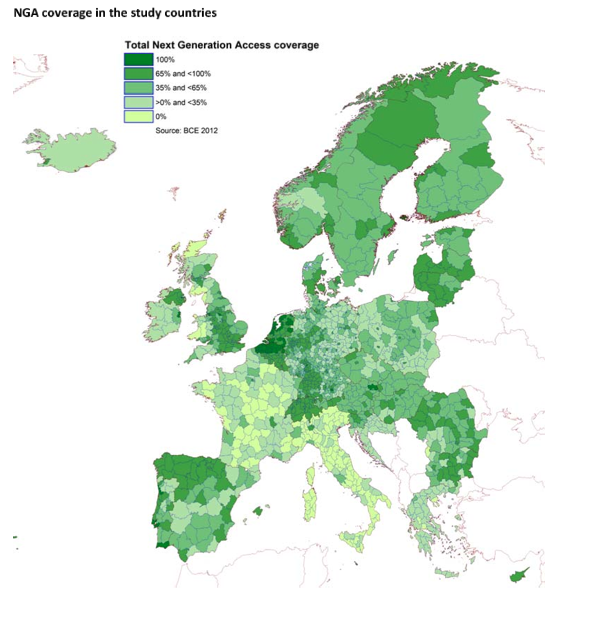
The coverage map of next generation broadband coverage shows that some countries are much better covered than others. There is still work to be done by network operators to deploy advanced technologies to meet the 30 Mbps expectation of the Digital agenda.
Multipath RTP
Multipath TCP enables communicating nodes to use different interfaces and paths to reliably exchange data. In today’s Internet, most applications use TCP and can benefit from Multipath TCP. However, multimedia applications often use the Real Time Transport (RTP) on top of UDP. A few years after the initial work on Multipath TCP, researchers at Aalto university analyzed how RTP to be extended to support multiple path. Thanks to their work, there is now a backward compatible extension of RTP that can be used on multihomed hosts. This extension will be important to access mobile streaming websites that use the Real Time Streaming Protocol (RTSP).
The Software Defined Operator
Network operators are reconsidering the architecture of their networks to better address the quickly evolving traffic and connectivity requirements. DT is one of them and in a recent presentation at the Bell Labs Open Days in Antwerp, Axel Clauberg gave his vision of the next generation ISP network. This is not the first presentation that DT employees give on their TerraStream vision for future networks. However, there are some points that are worth being noted.
Lessons learned from SDN experiments and deployments
The scientific literature is full of papers that propose a new technique that (sometimes only slightly) improves the state of the art and evaluate its performance (by means of mathematical models, simulations are rarely experiments with real systems). During the last years, Software Defined Networking has seen a growing interest in both the scientific community and among vendors. Initially proposed as Stanford University, Software Defined Networking, aims at changing how networks are managed and operated. Today’s networks are composed of off-the-shelf devices that support standardized protocols with proprietary software and hardware implementations. Networked devices implement the data plane to forwarding packet and the control plane to correctly compute their forwarding table. Both planes are today implemented directly on the devices.
Software Defined Networking proposes to completely change how networks are built and managed. Networked devices still implement the data plane in hardware, but this data plane, or more precisely the forwarding table that controls its operation, is exposed through a simple API to software defined by the network operator to manage the network. This software runs on a controller and controls the update of the forwarding tables and the creation/removal of flows through the network according to policies defined by the network operator. Many papers have already been written on Software Defined Networking and entire workshops are already dedicated to this field.
A recently published paper, Maturing of OpenFlow and software-defined networking through deployments, written by M. Kobayashi and his colleagues analyzes Software Defined Networking from a different angle. This paper does not present a new contribution. Instead, it takes on step back and discusses the lessons that the networking group at Stanford have learned from designing, using and experimenting with the first Software Defined Networks that are used by real users. The paper discusses many of the projects carried out at Stanford in different phases, from the small lab experiments to international wide-area networks and using SDN for production traffic. For each phase, and this is probably the most interesting part of the paper, the authors highlight several of the lessons that they have learned from these deployments. Several of these lessons are worth being highlighted :
- the size of the forwarding table on Openflow switches matters
- the embedded CPU on networking devices is a barreer to innovation
- virtualization and slicing and important when deployments are considered
- the interactions between Openflow and existing protocols such as STP can cause problems. Still, it is unlikely that existing control plane protocols will disappear soon.
This paper is a must-read for researchers working on Software Defined Networks because it provides informations that are rarely discussed in scientific papers. Furthermore, it shows that eating your own dog food, i.e. really implementing and using the solutions that we propose in out papers is useful and has value.
Bibliography
[1] Masayoshi Kobayashi, Srini Seetharaman, Guru Parulkar, Guido Appenzeller, Joseph Little, Johan van Reijendam, Paul Weissmann, Nick McKeown, Maturing of OpenFlow and software-defined networking through deployments, Computer Networks, Available online 18 November 2013, ISSN 1389-1286, http://dx.doi.org/10.1016/j.bjp.2013.10.011.
Another type of attack on Multipath TCP ?
In a recent paper presented at Hotnets, M. Zubair Shafiq and his colleagues discuss a new type of “attack” on Multipath TCP.
When the paper was announced on the Multipath TCP mailing list, I was somewhat concerned by the title. However, after having read it in details, I do not consider the inference “attack” discussed in this paper as a concern. The paper explains that thanks to Multipath TCP, it is possible for an operator to infer about the performance of “another operator” by observing the Multipath TCP packets that pass through its own network. The “attack” is discussed in the paper and some measurements are carried out in the lab to show that it is possible to infer some characteristics about the performance of the other network.
After having read the paper, I don’t think that the problem is severe and should be classified as an “attack”. First, if I want to test the performance of TCP in my competitor’s network, I can easily subscribe to this network, in particular for wireless networks that would likely benefit from Multipath TCP. There are even public measurements facilities that collect measurement data, see SamKnows, the FCC measurement app, speedtest or MLab.
More fundamentally, if an operator observes one subflow of a Multipath TCP connection, it cannot easily determine how many subflows are used in this Multipath TCP connection and what are the endpoints of these subflows. Without this information, it becomes more difficult to infer TCP performance in another specific network.
The technique proposed in the paper mainly considers the measurement throughput on each subflow as a time series whose evolution needs to be predicted. A passive measurement device could get more accurate predictions by looking at the packets that are exchanged, in particular the DATA level sequence number and acknowledgements. There is plenty of room to improve the inference technique described in this paper. Once Multipath TCP gets widely deployed and used for many applications, it might be possible to extend the technique to learn more about the performance of TCP in the global Internet.
The Multipath TCP buzz
The inclusion of Multipath TCP in iOS7 last week was a nice surprise for the designers and first implementors of the protocol. The initial announcement created a buzz that was echoed by many online publications :
- A little-Heralded New iOS7 Feature : Multipath TCP on http://slahdot.org
- Apple iOS 7 surprises as first with new multipath TCP connections on http://www.networkworld.com
- Apple’s iOS 7 includes a surprise: a ticket to the next generation of the internet on http://qz.com
- Apple found to be using advanced Multipath TCP networking in iOS 7 on http://appleinsider.com
- iOS 7 becomes first commercial software to support multipath TCP, allowing simultaneous Wi-Fi and cell network connections on http://9to5mac.com
- iOS 7 found to sport new networking tech on http://news.cnet.com
- Apple includes Multipath TCP networking in iOS 7
- Multipath TCP lets Siri seamlessly switch between Wi-Fi and 3G/LTE on http://arstechnica.com
- iOS 7 exploite le Wi-Fi et la 3G en meme temps on http://www.macworld.fr
The same information also appeared in news sites in Spanish, Norwegian, Japanese, Chinese, Portugese (see 1, 2, 3) and various blogs. See Google news search for recent links.
If you’ve seen postings about Multipath TCP in other major online or print publications, let me know.