Innovating with Multipath TCP
There is a huge difference between research and innovation. Research often means finding new and original results. In the networking community, this often means inventing new protocols, finding new alogorithms, collecting measurements, … Innovation is different. According to the business dictionnary, innovation is “The process of translating an idea or invention into a good or service that creates value or for which customers will pay.”
Multipath TCP is an interesting example of a research result that drives innovation. In 2013, Apple started to use it to improve the performance of the SiRi voice recognition application. Two years later, several researchers from the IP Networking Lab created the Tessares to develop hybrid access networks that rely on Multipath TCP to efficiently combine xDSL and cellular networks. The main target of these hybrid networks are rural areas where existing xDSL networks do not provide enough bandwidth to support the current needs of rural users. The xDSL network is then complemented with the LTE network to boost the bandwidth when required.
This technology has been standardised by the BBF as TR-348 Hybrid Access Broadband Architecture. It is now deployed in multiple countries where rural users benefit from improved Internet access.
A recent paper published in IEEE Communications Standards Magazine and entitled Increasing Broadband Reach with Hybrid Access Networks provides additional technical details about this Multipath TCP use case.
Contributing to Multipath TCP in six Ph.D. theses
Multipath TCP is a major extension TCP extension that has attracted a lot of interest from both academia, with more than one thousand citations for RFC 6824 and industry with deployments by Apple, Samsung, Huawei, LG, Tessares, … It received the 2019 ACM SIGCOMM’s Networking Systems award. The initial ideas on Multipath TCP emerged within the FP7 Trilogy funded by the European Commission and a large part of the work was carried out within UCLouvain’s IP Networking Lab During the last decade, six Ph.D. theses were granted with results that contributed to the different aspects of Multipath TCP.
- Sébastien Barré wrote the first implementation of Multipath TCP in the Linux kernel. His Ph.D. thesis, Implementation and assessment of Modern Host-based Multipath Solutions, describes this initial implementation and evaluates its performance. He later co-founded Tessares that deploys Multipath TCP solutions for network operators.
- Christoph Paasch moved our Multipath TCP implementation to the next level by designing many enhancements and contributing to the IETF. His Ph.D. thesis, Improving Multipath TCP remains the best reference for the Multipath TCP implementation in the Linux kernel. He then moved to Apple in California where he has pushed Multipath TCP further.
- Gregory Detal focused on making Multipath TCP easier to deploy with Multipath TCP proxies. His Ph.D. thesis, Evaluating and Improving the Deployability of Multipath TCP was the starting point for the creation of Tessares.
- Fabien Duchêne studied different use cases in his Ph.D. entitled Helping the Internet scale by leveraging path diversity. His solution to support Multipath TCP in load-balancers has been included in RFC 8684.
- Viet-Hoang Tran showed in his Ph.D. thesis entitled Measuring and extending Multipath TCP that it is possible to dynamically extend the Linux TCP and MPTCP implementations by using eBPF. A similar approach has been pushed by facebook engineers in the mainline Linux kernel.
- Quentin De Coninck started to work on improving Multipath TCP, but then designed Multipath QUIC and Pluginized QUIC in his Ph.D. entitled Flexible Multipath Transport Protocols
The history of Multipath TCP
During the last decade, we heavily contributed to the design, implementation and the deployment of Multipath TCP. I was interviewed by Russ White as part of the History of Networking podcast series to summarize the history of Multipath TCP. You can download this podcast from https://historyofnetworking.s3.amazonaws.com/Olivier+Bonaventure+-+MTCP.mp3
Multipath TCP : the first ten years
The research on Multipath TCP started a bit more than ten years ago with the launch of the FP7 Trilogy project. During this decade, Multipath TCP has evolved a lot. It has also generated a lot of interest within the scientific community with several hundreds of articles that use, extend or reference Multipath TCP. As an illustration of the scientific impact of Multipath TCP, the figure below shows the cumulative number of citations for the sequence of internet drafts that became RFC 6824 according to Google Scholar.
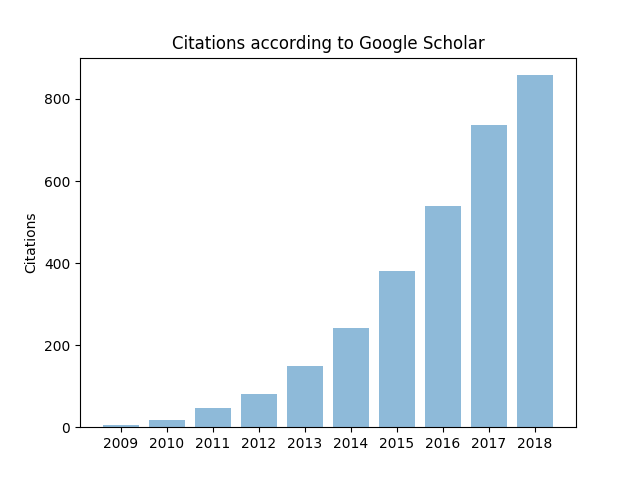
The industrial impact of Multipath TCP is also very important as Apple uses it on all iPhones and several network operators use it to create Hybrid Access Networks that combine xDSL and LTE to provide faster Internet services in rural areas.
On all the remaining days until Christmas, a new post will appear on the Multipath TCP blog to illustrate one particular aspect of Multipath TCP with pointers to relevant scientific papers, commercial deployments, … This series of blog posts will constitute a simple advent calendar that could be useful for network engineers and researchers who want to understand how this new protocol works and why it is becoming more and more important in today’s Internet.
How can universities contribute to future Internet protocols ? Our experience with Segment Routing
The Internet continues to evolve. Given its commercial importance, a large fraction of this evolution is driven by large telecommunications and cloud companies with input from various stakeholders such as network operators. In this growingly commercial Internet, some of my colleagues wondered the role that University researchers could play ? Different researchers have different strategies. Within the IP Networking Lab, we focus our research on protocols and techniques which can improve the Internet in the medium to long term. As most of the researchers of the group are Ph.D. students, it is important for them to address research problems that will remain relevant at the end of their thesis, typically after four years. The selection of a research topic is a strategic decision for any academic lab. While many labs focus on a single topic for decades and explore every of its aspects, I tend to switch the focus of the group every 5-7 years. During my Ph.D., I explored the interactions between TCP and ATM, but when I became professor, I did not consider that the topic for still relevant enough to encourage new Ph.D. students to continue to work on it. Looking at the evolution of the field, I decided to focus our work on traffic engineering techniques and the Border Gateway Protocol. This lead to very successful projects and Ph.D. theses. In 2008, the Trilogy project gave us the opportunity to work on new future Internet protocols. With a group a very talented Ph.D. students, we played a key role in the design, development and deployment of Multipath TCP. Its successes have exceeded our initial expectations.
However, despite the benefits of Multipath TCP, betting the future of the entire research group on a single protocol did not seem to be the right approach. In early 2013, I was impressed by a presentation that Clarence Filfils gave at NANOG. This presentation completely changed my view on MPLS. MPLS emerged in the 1990s from the early work on IP switching and tag switching. One of the early motivations for MPLS was the ability to reuse the ATM and frame relay switching fabrics that were, at that time, more powerful than their IP counterparts. When the MPLS shim header appeared, the IETF required MPLS to be agnostic of the underlying routing protocol and for this reason designed the LDP and RSVP-TE signalling protocols. Over the years, as MPLS networks grew, these two protocols became operational concerns.
Segment Routing was initially presented as a drastic simplification of the networking architecture. Instead of requiring the utilisation of specific signalling protocols, it relies on the existing link state routing protocols such as OSPF and IS-IS to distribute the MPLS labels. I saw that as a major breakthrough for future MPLS networks. Beyond the expected impact on networking protocols, Segment Routing brought a fundamental change to the way paths are computed in a network. A unique feature of Segment Routing compared to all the other networking technologies is that with Segment Routing a path between a source and a destination node is composed as a succession of shortest paths between intermediate nodes. With the MPLS variant of Segment Routing, these paths are identified by their MPLS label that is placed inside each packet. With the IPv6 variant of Segment Routing, these paths are encoded as a source route inside the IPv6 Segment Routing Header. This contrasts with popular networking architectures such as plain IP that uses a single shortest path between the source and the destination while MPLS with RSVP-TE can be configured to use any path. These different types of paths have lead to very different traffic engineering techniques. In pure IP networks, a popular technique is to tune the weights of the link-state routing protocol. With Segment Routing, the traffic engineering problem can be solved by using very different techniques. During the last years, we have proposed several innovative solutions to optimise the traffic flows in large networks.
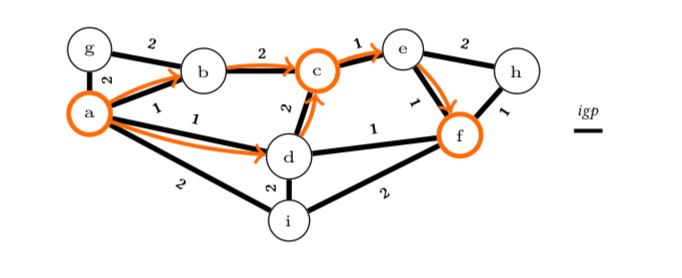
This is illustrated in the figure below. The numbers associated to the links are the IGP weights. With pure IP routing, the path from node a to node f is the shortest one, i.e. the one via node a. With RSVP-TE, any path can be constructed between node a and node f, e.g. a-g-b-c-e-f, but this requires state on all intermediate nodes. With Segment Routing, we trade the state in the routers with labels in the packets. A path is now a succession of shortest paths. For example, the figure below shows the a-c-f paths. To send packets along those paths, node a sends packets that contain two labels: (1) the label to reach node c and (2) the label to reach node f. The packets are first forwarded according to node c’s label and there are two shortest paths of equal cost between a and c. When they reach node c, it pops the top label and then packets are forwarded along the shortest path to reach node f.
A few research labs, including the IP Networking Lab have actively participated to the development of Segment Routing. Our research started almost at the same time as the initial work within the Spring IETF working group. Despite the visibility of this working group, we decided to not actively participate to the standardisation of the MPLS variant of Segment Routing. Instead, we focused our work on two different but very important aspects of Segment Routing. The first one is the design of innovative optimisation techniques that can be applied by network operators to leverage the unique characteristics of Segment Routing. The second one is the IPv6 variant of Segment Routing. Both problems were important and they were not the initial focus of IETF working group. This gave us enough time to carry research whose results could have an impact on the development of Segment Routing.
Let us start with the optimisation techniques. This work was carried out in collaboration with two colleagues: Yves Deville and Pierre Schaus. Our first approach to solve this problem was presented at SIGCOMM’15 in A Declarative and Expressive Approach to Control Forwarding Paths in Carrier-Grade Networks. This was the first important traffic engineering paper that leverages the unique features of Segment Routing. Renaud Hartert, the Ph.D. student who initiated this traffic engineering work, presented at INFOCOM’17 a faster solution in Expect the unexpected: Sub-second optimisation for segment routing. His Ph.D. thesis, Fast and scalable optimisation for segment routing, contains other unpublished techniques.
Another Ph.D. student, Francois Aubry explored other use cases than the classical traffic engineering problem. In SCMon: Leveraging Segment Routing to Improve Network Monitoring, presented at INFOCOM’16, he proposed a new technique to create efficient cycles that a monitoring node can used to verify the performance of a live network. His most recent paper that will be presented at Conext’18, Robustly Disjoint Paths with Segment Routing demonstrates that it is possible with Segment Routing to create disjoint paths that remain disjoints even after a link failure. He is currently preparing his Ph.D. thesis.
David Lebrun explored the networking aspects of Segment Routing during his Ph.D. He started his Ph.D. at the same time as the initial thinkings about the IPv6 variant of Segment Routing and has proposed several important contributions. He was the first to implement IPv6 Segment Routing in the Linux kernel. His implementation has heavily influenced several of the design choices that have shaped the specification of the IPv6 Segment Routing Header. His implementation has been described in Implementing IPv6 Segment Routing in the Linux Kernel and in his Ph.D. thesis. It has been included in the mainline Linux kernel since version 4.14. This implies that any Linux host can now use IPv6 Segment Routing. Besides this kernel implementation, David Lebrun has demonstrated in a paper that was presented at SOSR’18 how enterprise networks could leverage IPv6 Segment Routing.
Our most recent work has contributed to the utilisation of IPv6 Segment Routing to support Network Function Virtualisation or Service Function Chaining. The IPv6 variant of Segment Routing enables a very nice feature that is called network programming. With network programming, a router can expose network functions as IPv6 addresses and the packets that are sent towards those addresses are processed by a specific function on the router before being forwarded. This idea looks nice on paper and reminds older researchers of active networks that were a popular research topic around 2000. Within his Master thesis, Mathieu Xhonneux proposed to use eBPF to implement such network functions on Linux. His architecture is described in more details in Leveraging eBPF for programmable network functions with IPv6 Segment Routing with several use cases. It has also been accepted in the mainline Linux kernel. Another use case is described in Flexible failure detection and fast reroute using eBPF and SRv6.
Looking at out last five years of research on Segment Routing, I think that there are two important lessons that would be valid for other research groups willing to have impact on Internet protocols. First, it is important to have a critical mass of 3-4 Ph.D. students who can collaborate together and develop different aspects in their own thesis. The second lesson is the importance of releasing the artefacts associated to our research results. These artefacts encourage other researcher to expand our work. Our implementations that are now included in the official Linux kernel go beyond the simple reproducibility of our research results since anyone will be able to use our code.
This research on Segment Routing has been funded by the ARC-SDN project, FRIA Ph.D. fellowships and a URP grant from Cisco. It continues with a facebook grant.
Concrete steps to improve the reproducibility of networking research
Schloss Dagstuhl – Leibniz Center for Informatics is a well-known and important place for Computer Science. Since 1990, it is a meeting place for Computer Science researchers who spent a few days or a week discussing about interesting research issues in a small castle in South Germany. Dagstuhl is well-known for the high quality of its seminars.
Last week, together with kc Claffy, Daniel Karrenberg and Vaibhav Bajpai, I had the pleasure to organise a Dagstuhl seminar on Encouraging Reproducibility in Scientific Research of the Internet. As many fields of Science, networking research has some reproducibility issues. During the seminar, the thirty participants discussed on several very concrete steps to improve the reproducibility of networking research. This is a long-term objective that the community needs to tackle step by step to achieve a sustainable solution.

Several very excellent ideas where discussed during the seminar and some of them will materialise in the coming months. The first one is a review form for research artifacts that will be used for the evaluation of the artifacts of SIGCOMM-sponsored conferences in the coming weeks. It will probably be followed by a set of guidelines to help young researchers to carry out reproducible research and other more long-term ideas.
A printed ebook
In 2008, UCLouvain agreed to reduce my teaching load to let me concentrate on writing the open-source Computer Networking: Principles, Protocols and Practice ebook. Since then, this ebook has served as required textbook for basic networking courses at UCLouvain and at various universities. The ebook is completely open and available under a creative-commons license. This license enables anyone, including for-profit printing companies, to distribute and sell copies of the book. Honestly, I haven’t checked whether someone had decided to take the financial risk of printing copies of the book. With today’s print on demand solutions, the risk is very small.
While attending a Dagstuhl seminar on Encouraging Reproducibility in Scientific Research of the Internet, I visited their famous library, probably one of the best Computer Science libraries. I was delighted to see that they had bound copy of the first edition of Computer Networking: Principles, Protocols and Practice. This is the first time that I saw a copy of this book.


This printed version has been published by Textbook Equity.
A blog to complement university courses
When I was a student, university courses where an opportunity for the professor to teach all the important principles on a given topics to the students who registered for the course. At that time, students almost only used the course syllabus or one reference book. They rarely went to the library to seek additional information on any topic discussed by the professor. This forced the professor to be as complete as possible and cover all the important topics during the classes.
Today’s professors have a completely different job. Given the vast amount of information that is available to all students over the Internet, university courses have become a starting point that guide students in their exploration of the course topic. It remains important to teach the key principles to the student, but it becomes equally important to encourage them to explore the field by themselves. There are several activities that professors can organise in their classes to encourage the students to go further. For example, my networking course is based on the open-source Computer Networking: Principles, Protocols and Practice ebook. Initially, the ebook was distributed as a pdf file. The students were satisfied with the contents of the ebook, but they almost never spent time in the library to look at the books and articles referenced in the bibliography. This changed dramatically in 2011 after I modified the bibliography to include clickable URLs for most cited references. Since then, I observed that more and more students spent time to look at some references, including RFCs, to better understand specific parts of the course.
Another activity that I organise within the networking course to encourage students to explore the field is the detailed analysis of a popular website that each student has to carry out. During the last month of the semester, i.e. once the students has understood the basics of computer networking and some of the key protocols, each student has to apply his/her knowledge by writing a detailed four-page report that analyses the operation of a popular website. During the course, the students learns the basics of DNS, TLS, HTTP, TCP, IPv6 and they mobilise this knowledge to understand the protocol optimisations done by popular websites. They use standard tools such as the developper extensions of web browsers, dig, traceroute, wireshark, tcpdump, or openssl to interact with the website and analyse the protocol optimisation that it supports. During this analysis, they often see unexpected results that force them to understand in more details one of these protocols by looking at tutorials on the web, scientific articles or internet drafts and RFCs. With this kind of activity, the students gain a more in-depth knowlege of the Internet protocols that are explained during the course. More importantly, they also learn to find accurate technical information on the web, which is a very important skill for any computer scientist.
The exam is an important event for the students. It confirms that they have mastered the topic. However, the topics that were discussed during the course continue to evolve after the exam. While the basic principles of computer networking are stable, Internet protocols continue to evolve at a rapid pace. Various updates have been made to the Computer Networking: Principles, Protocols and Practice ebook. This ensures that future students will use up-to-date material to start their exploration of the networking field. However, former students are also interested in the evolution of the field and do not want to wait for the next edition of the ebook. For them, I have launched a companion blog for the ebook. On this blog, I summarise recent news, articles, or Internet drafts that could affect the evolution of the field. This blog is also available as an RSS feed.
TLS or HTTPS everywhere is not necessary the right answer
Since the revelations about the massive surveillance by Edward Snowden, we have observed a strong move towards increasing the utilisation of encryption to protect the end-to-end traffic exchanged by Internet hosts. Various Internet stakeholders have made strong move on recommending strong encryption, e.g. :
- The IETF has confirmed in RFC 7258 that pervasive monitoring is an attack and needs to be countered
- The EFF has promoted the utilisation of HTTPS through the HTTPS-everywhere campaign and browser extension
- The Let’s Encrypt campaign prepares a new certification authority to ease the utilisation of TLS
- Mozilla has announced plans to deprecate non-secure HTTP
- Most large web companies have announced plans to encrypt traffic between their datacenters
- …
Pervasive monitoring is not desirable and researchers should aim at finding solutions, but encrypting everything is not necessarily the best solution. As an Internet user, I am also very concerned by the massive surveillance that is conducted by various commercial companies.
Segment Routing in the Linux kernel
Segment Routing is a new packet forwarding technique which is being developed by the SPRING working group of the IETF. Until now, two packet forwarding techniques were supported by the IETF protocols :
- datagram mode with IPv4 and IPv6
- label swapping with MPLS
Segment Routing is a modern realisation of source routing that was supported by IPv4 in RFC 791 and initially in IPv6 RFC 2460. Source routing enables a source to indicate inside each packet that it sends a list of intermediate nodes to reach the final destination. Although rather old, this technique is not widely used today because it causes several security problems. For IPv6, various attacks against source routing were demonstrated in 2007. In the end, the IETF chose to deprecate source routing in IPv6 RFC 5095.
However, source routing has several very useful applications inside a controlled network such as an entreprise or a single ISP network. For this reason, the IETF has revived source routing and considers two data planes :
- IPv6
- MPLS