Hello 2017-2018 students !
A first warm-up with a video from Mark Handley about Spectre and Meltdown vulnerabilities.
Also, a very good introduction to a lot of things discussed in the course !
https://www.youtube.com/watch?v=m66EAgRMmi8
Hello 2017-2018 students !
A first warm-up with a video from Mark Handley about Spectre and Meltdown vulnerabilities.
Also, a very good introduction to a lot of things discussed in the course !
https://www.youtube.com/watch?v=m66EAgRMmi8
A shell, typically parse a command, then fork (duplicates itself).
The duplicated process replaces itself using Execvp by the program described in the command
The other process wait for the duplicated one to exit using waitpid. When that happens it prints the prompt again, ready for the next one to come. And the whole thing restarts again.
Not a very hard life.
Here are the important parts of the manpages of the 3 functions :
Fork
NAME
fork – create a child process
SYNOPSIS
#include <unistd.h>
pid_t fork(void);
DESCRIPTION
fork() creates a new process by duplicating the calling process. The
new process is referred to as the child process. The calling process
is referred to as the parent process.
The child process and the parent process run in separate memory spaces.
At the time of fork() both memory spaces have the same content.
RETURN VALUE
On success, the PID of the child process is returned in the parent, and
0 is returned in the child. On failure, -1 is returned in the parent,
no child process is created, and errno is set appropriately.
Execvp
EXEC(3) Linux Programmer’s Manual EXEC(3)
NAME
execvp – execute a file
SYNOPSIS
#include <unistd.h>
int execvp(const char *file, char *const argv[]);
DESCRIPTION
The execvp() function replaces the current process image with
a new process image.
The initial argument for this function is the name of a file that is
to be executed.
The const char *arg can be thought of as arg0, arg1, …, argn.
Together they describe a list of one or more pointers to null-termi‐
nated strings that represent the argument list available to the exe‐
cuted program. The first argument, by convention, should point to the
filename associated with the file being executed. The list of argu‐
ments must be terminated by a null pointer, and, since these are vari‐
adic functions, this pointer must be cast (char *) NULL.
RETURN VALUE
The exec() functions return only if an error has occurred. The return
value is -1, and errno is set to indicate the error.
waitpid
NAME
waitpid – wait for process to change state
SYNOPSIS
pid_t waitpid(pid_t pid, int *status, int options);
DESCRIPTION
The waitpid() system call suspends execution of the calling process
until a child specified by pid argument has changed state. By default,
waitpid() waits only for terminated children.
The first question to ask yourself is probably what the mkdir syscall does?
Obviously, it will create a new dir (thanks captain!) but is it only one piece of code for the whole kernel?
If I ask, the answer is no. First, there is one syscall entry per achitecture, so searching about mkdir in the arch will already show a lot entries.
But what’s a dir? Something which contains one or multiple files? Yes but no. Conceptually, the main purpose of the directory is to give names to files and allow to address them. If the name of the file was in the file structure, how to access it? Without folder you would only have an array of files without names… But I’m getting away from the question (just giving you an exam answer by the way…)
The dir, in practice is implemented differently in all file systems. So there is one different mkdir function per file system, and there is a lot of FS in the linux kernel… How the kernel knows which one to use? It uses something much like net_device_ops for a network device (OS 2015-2016), md_personality for an md array (OS 2014-2015) or sched_class for a scheduler (OS 2013-2014) : a structure of function pointers that the kernel can follow to accomplish some actions.
So a “grep -Ri mkdir” on the top level of the kernel will give you way too much results…
If you look at the syscall table, you’ll find that we often talk about sys_something, so searching for sys_mkdir could be a good idea…
Could be… Because you won’t find it. Why? You should remember half of my slides, or what I said in class, or … Well, that smells the macro… Cscope does not support them well, Eclipse does. But Eclipse can only resolve a macro usage, not search in reverse from the macro declarations (as far as I know).
Time to show your regular expression skills ! (You could also search for the macro defining the syscall directly…). We should have something called syscall and mkdir in the same line… So let’s search for sys [something] mkdir, or the reverse :
grep –exclude “*.o” -RiE “sys.*mkdir|mkdir.*sys”
–exclude *.o allows to avoid searching object files, R do the search recursively, i case insensitive, E use regular expressions.
That stills give too much results. Looking quickly through, you could add –exclude Documentation and arch as those two won’t contain the actual implementation. Another way is to search only in the fs folder, as we can think that the syscall implementation is something about file systems… Even if it will call a per-fs function.
Let’s do the later :
cd fs
grep --exclude "*.o" -RiE "sys.*mkdir|mkdir.*sys"
sysv/namei.c:static int sysv_mkdir(struct inode * dir, struct dentry *dentry, umode_t mode)
sysv/namei.c: .mkdir = sysv_mkdir,
Fichier binaire sysv/sysv.ko correspondant
tracefs/inode.c:static int tracefs_syscall_mkdir(struct inode *inode, struct dentry *dentry, umode_t mode)
tracefs/inode.c: .mkdir = tracefs_syscall_mkdir,
proc/root.c: proc_mkdir("sysvipc", NULL);
proc/proc_sysctl.c: proc_sys_root = proc_mkdir("sys", NULL);
namei.c:SYSCALL_DEFINE3(mkdirat, int, dfd, const char __user *, pathname, umode_t, mode)
namei.c:SYSCALL_DEFINE2(mkdir, const char __user *, pathname, umode_t, mode)
namei.c: return sys_mkdirat(AT_FDCWD, pathname, mode);
btrfs/ioctl.c: * sys_mkdirat and vfs_mkdir, but we only do a single component lookup
And it’s right in front of you 😉 The number to use at the end of the macro is quite obvious… But google can help you if you don’t find what it means.
Variable-size structures are helpful, because you can allocate a structure containing an array of an unkown (at compile time) size at the end. For example, a “nuda_conf” structure containing informations about an MD Array and a “dev_info” structure per disks. The number of disks is unknown at compile time, so the only solution is to use a kalloc/vmalloc. The classical solution is to do :
[code lang=”c”]
struct dev_info {
int whatever;
struct rdev* rdev;
}
struct nuda_conf {
char* name;
int whotever;
struct dev_info disks*
}
...
struct nuda_conf* conf;
conf = kzalloc(sizeof(struct nuda_conf));
conf->disks = kzalloc(sizeof(struct dev_info) * NUMER_OF_DISKS);
[/code]
But variable-size structures allows to do only one allocation :
[code lang=”c”]
struct nuda_conf {
char* name;
int whotever;
struct dev_info disks[0];
}
struct nuda_conf* conf;
conf = kzalloc(sizeof(struct nuda_conf) + sizeof(struct dev_info) * NUMBER_OF_DISKS);
[/code]
This will allocate the memory for the char* and the int of nuda_conf, and the memory for a number of “dev_info”. To access them, one can do conf->disks[N] where N is the disk index.
But, this is limited to one variable-size array. If you do :
[code lang=”c”]
struct nuda_conf {
char* name;
int whotever;
struct dev_info disks[0];
struct indirection_line indirection_table[0];
}
[/code]
The “indirection_table” and the “disks” pointer will point to the same location ! Even if you allocate size for both ! The solution is either to use a classical pointer as in the first example, or handle the memory access yourself :
[code lang=”c”]
struct nuda_conf {
char* name;
int whotever;
}
...
conf = kzalloc (sizeof(struct nuda_conf) + sizeof(struct dev_info) * NUMBER_OF_DISKS + sizeof(struct indirection_line)*NUMBER_OF_CHUNKS);
struct dev_info* disks = (struct dev_info*)(conf + 1);
struct indirection_line* indirection_table = (struct dev_info*)(disks + NUMBER_OF_DISKS);
[/code]
But there is no interest in doing so, and both disks and indirection_table pointers have to be manually computed each time you need them… The use for that is really really really specific (dynamic metadata in packets for example).
Entries in the /sys folder are represented by “struct kobject“.
A kobject is … a kernel object. So it can be anything. Regarding the /sys system, kobject can be more or less thinked as a “folder” of /sys. To obtain the “kobject” entry for /sys of an md device, one can do &disk_to_dev(mddev->gendisk)->kobj. This object will handle the “folder” /sys/block/md/mdX/ where X is the number of the md device.
To initialize your own kobject and add it as a child of the kobject of the mddev, one can use kobject_init_and_add(yourobject, &yourobect_type,
&disk_to_dev(mddev->gendisk)->kobj, “%s”, “foldername”); In practice this will create a folder named “foldername” in /sys/block/md/mdX/.
“yourobject” should be a pointer to your kobject. It must be persistent, allocated with kmalloc or something like that and not in your function stack, even if you don’t plan to modify it. As kobject are more or less anything, you have to describe your kobject by passing to kobject_init_and_add a struct kobj_type
static struct kobj_type myobject_ktype = {
.release = release_function,
.sysfs_ops = &myobject_sysfs_ops,
};
release is the function which will be called when it’s time to destroy your kobject, while sysfs_ops is a struct sys_ops. We’ll come back to them later.
The “files” in your sys folder are represented by struct attribute. You have two choices here. Either the files in your folder do not change, and you add all the attribute as the “default list”of attributesof your kobject before the kobject initialisation , or you start with an empty kobject (or with some default files in the list but not all) and you add some files after kobject initialization using sysfs_create_file(yourobject, attr); where attr is a pointer to the attribute that you want to add. We’ll consider that all files are known in advance and we’ll put everything in the “default” list.
The “default” list is more a default array and is referenced via yourobject_ktype.default_attr . It is a pointer to the array of pointer to attributes. Yes, re-read that sentence twice 😉 It means you’ll give an array of pointer to attributes and not an array of attributes.
struct attribute **all_attrs;
all_attrs = kzalloc(sizeof(struct attribute *) * number_of_files);
attrs = kzalloc(sizeof(struct attribute) * number_of_files);
[fill attrs]
for (i = 0; i < number_of_files;i++)
all_attrs[i] = &attrs[i];
yourobject_ktype.default_attrs =all_attrs;
If we look at struct attributes it contains :
struct attribute {
const char *name;
mode_t mode;
};
You should find by yourself how to initialize the attrs. Note that name is a char pointer, and in noway can store character themselves. So you need to allocate somewhere all the names of your attributes, and obviously not on your function stack…
Now, let’s go back to the myobject_sysfs_ops which describes how to read and write to these attributes
The main two functions in the sys_ops are show an store
static const struct sysfs_ops myobject_sysfs_ops = {
.show = myobject_attr_show,
.store = myobject_attr_store,
};
These two functions will be called when any kobject attr is read or written in your kobject entry. Let’s see the show function :
static ssize_t
myobject_attr_show(struct kobject *kobj, struct attribute *attr, char *page)
{}
kobj is the pointer to your kobject, the attr is the attribute the user is trying to read and the page is a pointer to a space where you should print the content which was trying to be read.
The function container_of() is very usefull and often used in this case. Let’s say your kobject is stored in another structure, that we will call “struct conf” in our example. To recover the conf storing the kobject, one can do :
struct conf* conf = container_of(kobj, struct conf, kobj);
And you can use the attribute name to find what to write in the page.
This should be sufficient for most usage, using some tricks to respond according the attribute name.
If the treatment need to be specific according to the attribute/file, or if you absolutely need to store some data with each attribute, you have to allocate another bigger structure which contains the struct attr, this explains by the way why you give pointer to attributes and not an array of attributes to the ktype, because attributes could be scattered inside an array of a bigger structure. As an exemple, here the per-file structure of the md driver :
struct md_sysfs_entry {
struct attribute attr;
ssize_t (*show)(struct mddev *, char *);
ssize_t (*store)(struct mddev *, const char *, size_t);
};
The default_attributes cointains pointers to all the md_sysfs_entry->attr. And the show function of the kobject use cointainer_of() to find the md_sysfs_entry containing the attr. Then it calls the specific show and store functions of the md_sysfs_entry instead of doing something similar for all attributes.
If you use GIT, the kernel make system will append a “+” at the end of your kernel version. So some commands to install your kernel should be different like “update-initramfs -k 3.2.66+ -u” and of course, uname will show 3.2.66+
The students of INFO-0940 were asked to remove a task from it’s current scheduler class when calling a new syscall and put it back when we call again that syscall. The question is : what to do if the task is currently sleeping? Cause the timer will expire at one moment and maybe put back the state to TASK_RUNNING and run the task which should haven’t been able to run again. So either it expires after the processus is back in its previous scheduler, and that’s okay as it will reset it in a runnable state. Or it expires while it’s still removed, and that’s a problem as it will put it back in its previous state (or not, depending on how the syscall is implemented).
Warning : this post is just the result of a quick look. More to give you some ideas and basis for understanding the sleeping mechanism.
So we should try to understand how sleep works.
Let’s look at the nanosleep syscall (which is called when you user sleep() or usleep() functions in C).
SYSCALL_DEFINE2(nanosleep, struct timespec __user *, rqtp,
struct timespec __user *, rmtp)
{
struct timespec tu;
if (copy_from_user(&tu, rqtp, sizeof(tu)))
return -EFAULT;
if (!timespec_valid(&tu))
return -EINVAL;
return hrtimer_nanosleep(&tu, rmtp, HRTIMER_MODE_REL, CLOCK_MONOTONIC);
}
It copies the userspace data, check that the time is valid and call hrtimer_nanosleep.
long hrtimer_nanosleep(struct timespec *rqtp, struct timespec __user *rmtp,
const enum hrtimer_mode mode, const clockid_t clockid)
{
struct restart_block *restart;
struct hrtimer_sleeper t;
int ret = 0;
unsigned long slack;
slack = current->timer_slack_ns;
if (rt_task(current))
slack = 0;
hrtimer_init_on_stack(&t.timer, clockid, mode);
hrtimer_set_expires_range_ns(&t.timer, timespec_to_ktime(*rqtp), slack);
if (do_nanosleep(&t, mode))
goto out;
/* Absolute timers do not update the rmtp value and restart: */
if (mode == HRTIMER_MODE_ABS) {
ret = -ERESTARTNOHAND;
goto out;
}
if (rmtp) {
ret = update_rmtp(&t.timer, rmtp);
if (ret <= 0)
goto out;
}
restart = ¤t_thread_info()->restart_block;
restart->fn = hrtimer_nanosleep_restart;
restart->nanosleep.clockid = t.timer.base->clockid;
restart->nanosleep.rmtp = rmtp;
restart->nanosleep.expires = hrtimer_get_expires_tv64(&t.timer);
ret = -ERESTART_RESTARTBLOCK;
out:
destroy_hrtimer_on_stack(&t.timer);
return ret;
}
It initialize a timer and call do_nanosleep giving it the timer. After do_nanosleep it will destroy/free the timer structure.
static int __sched do_nanosleep(struct hrtimer_sleeper *t, enum hrtimer_mode mode)
{
hrtimer_init_sleeper(t, current);
do {
set_current_state(TASK_INTERRUPTIBLE);
hrtimer_start_expires(&t->timer, mode);
if (!hrtimer_active(&t->timer))
t->task = NULL;
if (likely(t->task))
schedule();
hrtimer_cancel(&t->timer);
mode = HRTIMER_MODE_ABS;
} while (t->task && !signal_pending(current));
__set_current_state(TASK_RUNNING);
return t->task == NULL;
}
This is the interesting part.
The first thing done is calling hrtimer_init_sleeper(); which will set parameters of the timer to call the function hrtimer_wakeup when the timer expires, and specify the task to wakeup at that time. hrtimer_wakeup will simply set the task to NULL and call wake_up_process() on that task. We’ll come back to wake_up_process(task) later.
We see that after that the state is changed to TASK_INTERRUPTIBLE. Then it starts the timer strictly speaking, and go in schedule().
Remember that schedule(), before scheduling a new task, will test the state of the current (which is now “previous”) task, and if the state is not TASK_RUNNING, it will remove that task from its runqueue (and that is the case as it is in the TASK_INTERRUPTIBLE state).
Schedule() goes on and start scheduling another task, if there is not, it will run the “idle” task.
At some point, the timer will expire. The timer rely on an hardware timer which will cause an interrupt, leaving any current task to process the interrupt handler (this is not the schedule() handler and so on !). The interrupt handler for the hardware timer is hrtimer_interrupt() which will run hrtimer_wakeup() for all expired timer. As said before, outr timer for the sleeping mechanism will set the timer task as NULL, and call wake_up_process(). But that functions just put back the process in the runqueue and set its state to TASK_RUNNING, not actually scheduling it. The interrupt handler will finish and the CPU will go back to it’s currently running process (maybe the idle process, running the cpu_idle() function).
That currently running process will eventually finish its processing or be preempted (the normal scheduling mechanism), and the process which was sleeping will re-run again when it will be picked again by pick_next_task().
But where will this process restart? After the sleep() or usleep() call? No ! Where it was… in the nanosleep syscall. What does the syscall do after its call to schedule()? Put the state back to TASK_RUNNING and effectively running. That seems obvious as we said before that the syscall is taking care of destroying the timer structure, so it should not restart after the syscall.
Note that I skipped the part where do_nanosleep() is looping and so on… I tried usleep(1) and sleep(1), and the loop never happend. I suspect it’s for very long timers, the kernel would’nt launch a timer of 1 hour long… But it’s just a guess.
This procedure is only with cable, not for wifi
First check that your interface is up with the command “sudo ifconfig” :
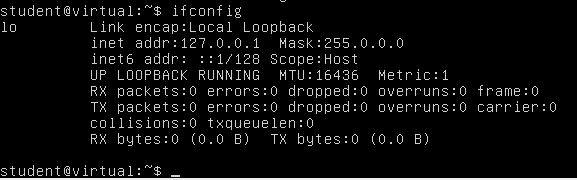
If like in this screenshot you do not see an interface named “ethXXX“, you have to start the interface manually.
To found which of eth0, eth1, … your network card is, you can type “dmesg | grep eth”
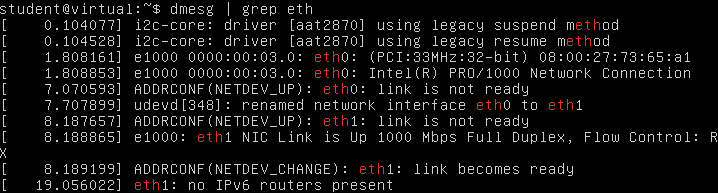
We see here that the card “Intel Pro/1000” takes the “eth0” interface name. But it’s later renamed to “eth1“.
So our interface here is eth1, to bring it up, simply run “sudo ifconfig eth1 up”.
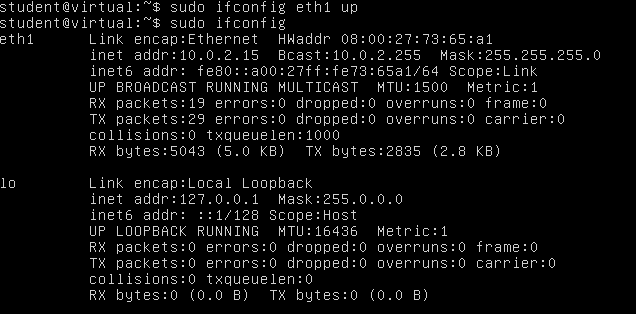
You may not have an IP Adress automatically like in this screenshot. If it’s the case, simply type “sudo dhclient eth1” to get one with DHCP.
If it doesn’t work, try to directly ping an IP address like google’s dns server 8.8.8.8 with the command “ping 8.8.8.8“. If it works, you probably have a nameserver problem. Simply add the line “nameserver 8.8.8.8” in /etc/resolv.conf
On ubuntu, if your system boots without network in failsafe mode, it will wait a long time for network to be available. In many case, this won’t help much…
Moreover, if you’re trying to do things like kernel compiling and for some reason you can’t see the boot log (including this “Waiting for network configuration” message), you’ll have the impression of being stuck with a bad kernel, but in fact it is just waiting 120 seconds…
Just edit the file sudo vi /etc/init/failsafe.conf and remove all “sleep” instructions. The message will be displayed but it won’t wait any time.
To repair you network problems, you might want to check this post and this post.
–> Ugly but okay in a development virtual machine
Launch the command “sudo visudo” in a terminal.
Add at the end :
student ALL=(ALL) NOPASSWD: ALL
And student will have no password prompt when using sudo