An ethernet packet is made in layers. Each layer is inside another layer.
The content of the skbuff created in e1000_clean_rx_irq is the whole ethernet frame. The Ethernet frame starts with an ethernet header, and then contains the ethernet payload.
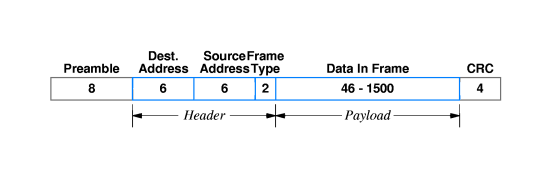
You do not receive the preamble (it’s just data to mark the beginning of the frame, always the same so useless to copy) and usually not the CRC either as all NICs can check it is correct for you (it will be removed in e1000_main.c:4451 if it’s there.)
Then how to know what’s in the data? Well, it will be given by two bytes starting from the 12th byte.
The known types are defined in if_ether.h, for example you can find the type of the IP packets there :
#define ETH_P_IP 0x0800 /* Internet Protocol packet */
So you know that somewhere, the “thing” handling the packets of the IP protocol will check that the type equals ETH_P_IP. It will in fact check if the type is cpu_to_be16(ETH_P_IP), because in the network, bytes are big-endian, while the CPU use little-endian. It means that in the network, 0x0800 will be 0x0080 as the most significant byte will be on the right. There is a lot of packets types, not just IP. Do not expect to find a “if (type == cpu_to_be16(ETH_P_IP))”… The kernel use a list of structure of known packet type and check the whole list against the actual packet type.
The kernel will call the handler defined for the specific protocol matching the IP packet.
The same scheme applies more or less for every layer, as the IP packet itself is also composed of a header with a type, and some data. And inside it there is again a UDP, TCP, ICMP, … packet with again a header and some data.
For example the type of the payload of the IP packet is given as a unique byte (so no byte order problem here) in the 9th byte of the IP header :
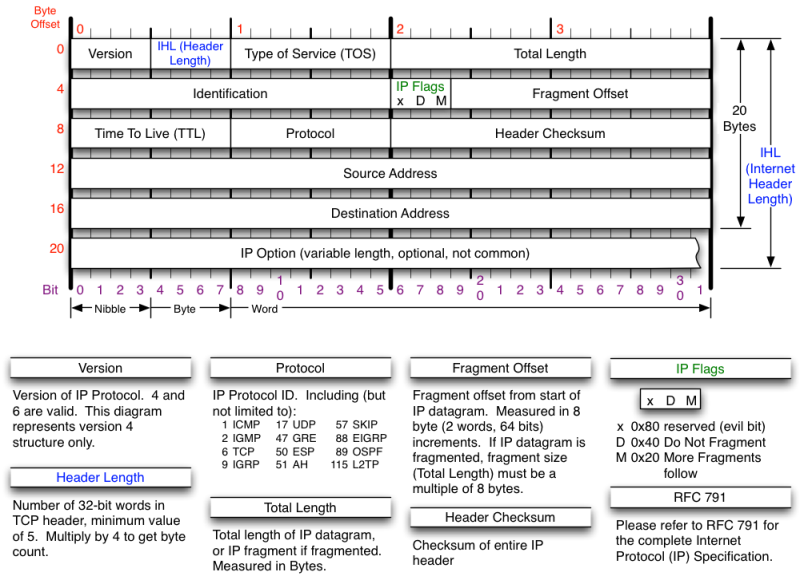
As there is only 256 possible types, the linux kernel use a table, and not a list as it allows to directly jump to good “sub” ip layer handler such as the one for UDP, TCP, …
IP protocols are defined in in.h for example we have IPPROTO_UDP = 17, /* User Datagram Protocol */ at line 40, which tells us that 17 is the UDP protocol. Again, a quick search on who use IPPROTO_UDP in the /net/ipv4 folder will tell us who is defining some kind of handler to handle that kind of packets with the IP protocol set to 17. A hint : there is a function which will set the good index of the “protocol table” to the structure containing informations about the protocol. So it’s not like the ethernet layer where the list contains the type and the function, here the protocol number is not in the handler structure 😉